S pomočjo katerega se modelirajo številni realni procesi. In najpogostejši primer je urnik javnega prevoza. Recimo avtobus (trolejbus/tramvaj) hodite v intervalih po 10 minut in se ob naključnem času ustavite. Kakšna je verjetnost, da bo avtobus prispel v 1 minuti? Očitno 1/10. In verjetnost, da boste morali čakati 4-5 minut? Enako . Kolikšna je verjetnost, da bo moral avtobus čakati več kot 9 minut? Ena desetina!
Razmislite o nekaterih končno interval, naj bo za določenost segment . če naključna vrednost ima konstantna gostota verjetnosti na danem segmentu in ničelno gostoto zunaj njega, potem pravimo, da je porazdeljen enakomerno. V tem primeru bo funkcija gostote strogo definirana: 
Dejansko, če je dolžina segmenta (glej risbo) je , potem je vrednost neizogibno enaka - da bi dobili površino enote pravokotnika, in opazili smo znana lastnina:
Preverimo formalno:
, h.t.p. Z verjetnostnega vidika to pomeni, da je naključna spremenljivka zanesljivo bo zavzel eno od vrednosti segmenta ..., eh, počasi postajam dolgočasen starec =)
Bistvo enotnosti je, da ne glede na notranjo vrzel fiksna dolžina nismo upoštevali (zapomnite si minute "avtobusa")- verjetnost, da bo naključna spremenljivka prevzela vrednost iz tega intervala, bo enaka. Na risbi sem zasenčil tri takšne verjetnosti - še enkrat opozarjam na dejstvo, da določajo jih območja, ne vrednosti funkcij!
Razmislite o tipični nalogi:
Primer 1
Zvezna naključna spremenljivka je podana z gostoto porazdelitve: ![]()
Poiščite konstanto , izračunajte in sestavite porazdelitveno funkcijo. Zgradite grafikone. Najti
Z drugimi besedami, vse, o čemer lahko sanjate :)
rešitev: saj na intervalu (končni interval) ![]() , potem ima naključna spremenljivka enakomerno porazdelitev, vrednost "ce" pa je mogoče najti z neposredno formulo
, potem ima naključna spremenljivka enakomerno porazdelitev, vrednost "ce" pa je mogoče najti z neposredno formulo ![]() . Vendar je bolje na splošno - z uporabo lastnosti:
. Vendar je bolje na splošno - z uporabo lastnosti:
… zakaj je bolje? Nič več vprašanj ;)
Torej je funkcija gostote: 
Naredimo trik. Vrednote nemogoče
, zato so na dnu postavljene krepke pike: 
Kot hitro preverjanje izračunajmo površino pravokotnika: ![]() , h.t.p.
, h.t.p.
Najdimo pričakovana vrednost, in verjetno že ugibate, čemu je enako. Spomnimo se "10-minutnega" avtobusa: če naključno ustavi se za mnogo, veliko dni, potem me reši povprečje počakati morate 5 minut.
Da, tako je - pričakovanje bi moralo biti točno na sredini intervala "dogodka":
, kot je bilo pričakovano.
Disperzijo izračunamo z formula ![]() . In tukaj potrebujete oko in oko pri izračunu integrala:
. In tukaj potrebujete oko in oko pri izračunu integrala:
torej disperzija: ![]()
Sestavljajmo distribucijska funkcija ![]() . Tukaj ni nič novega:
. Tukaj ni nič novega:
1) če , potem in ![]() ;
;
2) če , potem in:
3) in končno pri ![]() , Zato:
, Zato:
Kot rezultat: 
Izvedimo risbo: 
Na intervalu "v živo" distribucijska funkcija raste linearno, in to je še en znak, da imamo enakomerno porazdeljeno naključno spremenljivko. No, kljub vsemu še vedno izpeljanka linearna funkcija- je stalnica.
Zahtevano verjetnost je mogoče izračunati na dva načina z uporabo najdene porazdelitvene funkcije:
ali z uporabo določenega integrala gostote: 
Komur je všeč.
In tukaj lahko tudi pišete odgovor: , , grafi so zgrajeni vzdolž rešitve.
, grafi so zgrajeni vzdolž rešitve.
... "je možno", saj za njeno odsotnost običajno ne kaznujejo. Običajno ;)
Obstajajo posebne formule za izračun in enotno naključno spremenljivko, predlagam, da jih izpeljete sami:
Primer 2
Zvezna naključna spremenljivka, definirana z gostoto  .
.
Izračunajte matematično pričakovanje in varianco. Poenostavite rezultate (formule za skrajšano množenje pomagati).
Priročno je uporabiti dobljene formule za preverjanje, zlasti preverite težavo, ki ste jo pravkar rešili, tako da vanje nadomestite določene vrednosti "a" in "b". Kratka rešitev na dnu strani.
In na koncu lekcije bomo analizirali nekaj "besedilnih" nalog:
Primer 3
Vrednost delitve skale merilnega instrumenta je 0,2. Odčitki instrumenta so zaokroženi na najbližji cel razdelek. Ob predpostavki, da so napake zaokroževanja enakomerno porazdeljene, poiščite verjetnost, da pri naslednji meritvi ne bo presegla 0,04.
Za boljše razumevanje rešitve Predstavljajte si, da je to nekakšna mehanska naprava s puščico, na primer tehtnica z vrednostjo delitve 0,2 kg, in moramo stehtati prašiča v vreči. A ne zato, da bi ugotovili njegovo debelost - zdaj bo pomembno, KJE se bo puščica ustavila med dvema sosednjima razdelkoma.
Razmislite o naključni spremenljivki - razdalja puščice izklopljene najbližji levi oddelek. Ali od najbližje desne, ni pomembno.
Sestavimo funkcijo gostote verjetnosti:
1) Ker razdalja ne more biti negativna, potem na intervalu . Logično.
2) Iz pogoja sledi, da puščica tehtnice z enako verjetno se lahko ustavi kjer koli med razdelki *
, vključno s samimi razdelki, in torej na intervalu : ![]()
* To je bistveni pogoj. Tako bomo na primer pri tehtanju kosov vate ali kilogramskih zavitkov soli opazili enakomernost v precej ožjih intervalih.
3) In ker razdalja od NAJBLIŽJEGA levega razdelka ne more biti večja od 0,2, potem je tudi for nič.
Torej: 
Treba je poudariti, da nas nihče ni vprašal o funkciji gostote in sem njeno celotno konstrukcijo podal izključno v kognitivnih vezjih. Ko končate nalogo, je dovolj, da zapišete le 2. odstavek.
Zdaj pa odgovorimo na vprašanje problema. Kdaj napaka zaokroževanja na najbližji deljenj ne presega 0,04? To se bo zgodilo, ko se puščica ne ustavi več kot 0,04 od levega razdelka na desni oz ne dlje kot 0,04 od desnega razdelka levo. Na risbi sem zasenčil ustrezna področja: 
Še vedno je treba najti ta področja s pomočjo integralov. Načeloma jih je mogoče izračunati tudi "po šolsko" (kot ploščine pravokotnikov), a preprostost ne najde vedno razumevanja;)
Avtor: adicijski izrek za verjetnosti nekompatibilnih dogodkov:
- verjetnost, da napaka zaokroževanja ne bo presegla 0,04 (40 gramov za naš primer)
Lahko je razumeti, da je največja možna napaka pri zaokroževanju 0,1 (100 gramov) in torej verjetnost, da napaka zaokroževanja ne bo presegla 0,1 je enako ena. In iz tega, mimogrede, sledi še en, lažji način reševanja, pri katerem morate upoštevati naključno spremenljivko – napaka pri zaokroževanju na najbližje deljenje. Ampak prvi mi je padel na misel :)
Odgovori: 0,4
In še ena točka naloge. Pogoj lahko vsebuje napake. ne zaokroževanje, ampak o naključen napake same meritve, ki sta običajno (vendar ne vedno), se porazdelijo po običajnem zakonu. torej Samo ena beseda lahko spremeni vaše mnenje! Bodite pozorni in se poglobite v pomen nalog!
In ko gre vse v krogu, nas noge pripeljejo na isto postajo:
Primer 4
Avtobusi določene proge vozijo strogo po voznem redu in z intervalom 7 minut. Sestavite funkcijo gostote naključne spremenljivke - čakalne dobe potnika, ki se je naključno približal avtobusni postaji, na naslednji avtobus. Poiščite verjetnost, da ne bo čakal na avtobus več kot tri minute. Poiščite porazdelitveno funkcijo in pojasnite njen smiselni pomen.
Kot primer zvezne naključne spremenljivke razmislite o naključni spremenljivki X, enakomerno porazdeljeni po intervalu (a; b). Pravimo, da je naključna spremenljivka X enakomerno porazdeljena na intervalu (a; b), če njegova porazdelitvena gostota na tem intervalu ni konstantna:
Iz normalizacijskega pogoja določimo vrednost konstante c . Območje pod krivuljo gostote porazdelitve mora biti enako ena, v našem primeru pa je to območje pravokotnika z osnovo (b - α) in višino c (slika 1). 
riž. 1 Enakomerna gostota porazdelitve
Od tu najdemo vrednost konstante c: ![]()
Torej je gostota enakomerno porazdeljene naključne spremenljivke enaka 
Poiščimo porazdelitveno funkcijo po formuli:
1) za ![]()
2) za
3) za 0+1+0=1.
torej 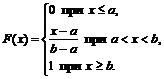
Porazdelitvena funkcija je zvezna in ne pada (slika 2). 
riž. 2 Porazdelitvena funkcija enakomerno porazdeljene naključne spremenljivke
Najdimo matematično pričakovanje enakomerno porazdeljene naključne spremenljivke po formuli:
Varianca enakomerne porazdelitve se izračuna po formuli in je enako
Primer #1. Vrednost razdelka merilnega instrumenta je 0,2. Odčitki instrumenta so zaokroženi na najbližji cel razdelek. Poiščite verjetnost, da bo pri branju prišlo do napake: a) manjša od 0,04; b) velika 0,02
rešitev. Napaka zaokroževanja je naključna spremenljivka, ki je enakomerno porazdeljena v intervalu med sosednjimi celimi delitvami. Kot takšno delitev upoštevajte interval (0; 0,2) (slika a). Zaokroževanje se lahko izvede tako proti levi meji - 0, kot proti desni - 0,2, kar pomeni, da je lahko napaka manjša ali enaka 0,04 dvakrat, kar je treba upoštevati pri izračunu verjetnosti: 

P = 0,2 + 0,2 = 0,4
V drugem primeru lahko vrednost napake tudi presega 0,02 na obeh mejah delitve, to pomeni, da je lahko večja od 0,02 ali manjša od 0,18. 
Potem je verjetnost napake, kot je ta:
Primer #2. Predpostavljeno je bilo, da je stabilnost gospodarskega položaja v državi (odsotnost vojn, naravnih nesreč itd.) V zadnjih 50 letih mogoče oceniti po naravi porazdelitve prebivalstva po starosti: v mirnem položaju, mora biti uniforma. Kot rezultat študije so bili za eno od držav pridobljeni naslednji podatki.
Ali obstaja razlog za domnevo, da so bile v državi nestabilne razmere?Odločitev izvedemo s pomočjo kalkulatorja Preverjanje hipotez. Tabela za izračun indikatorjev.
| Skupine | Sredina intervala, x i | Količina, fi | x i * f i | Kumulativna frekvenca, S | |x - x cf |*f | (x - x sr) 2 *f | Frekvenca, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Povprečna teža
Indikatorji variacije.
Absolutne stopnje variacije.
Razpon variacije je razlika med največjo in najmanjšo vrednostjo atributa primarne serije.
R = X max - X min
R=70 - 0=70
Razpršenost- označuje mero razpršenosti okoli svoje srednje vrednosti (mero razpršenosti, tj. odstopanje od srednje vrednosti).

Standardni odklon.
Vsaka vrednost niza se od povprečne vrednosti 43 ne razlikuje za več kot 23,92
Preizkušanje hipotez o vrsti porazdelitve.
4. Preizkušanje hipoteze o enakomerna porazdelitev splošne populacije.
Da bi preverili hipotezo o enakomerni porazdelitvi X, tj. po zakonu: f(x) = 1/(b-a) v intervalu (a,b)
potrebno:
1. Ocenite parametra a in b - konca intervala, v katerem so bile opažene možne vrednosti X, po formulah (znak * označuje ocene parametrov):
2. Poiščite gostoto verjetnosti ocenjene porazdelitve f(x) = 1/(b * - a *)
3. Poiščite teoretične frekvence:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Primerjajte empirične in teoretične frekvence s Pearsonovim testom ob predpostavki števila prostostnih stopenj k = s-3, kjer je s število začetnih intervalov vzorčenja; če pa je bila narejena kombinacija majhnih frekvenc in torej samih intervalov, potem je s število preostalih intervalov po kombinaciji.
rešitev:
1. Poiščite ocene parametrov a * in b * enotne porazdelitve z uporabo formul:
2. Poiščite gostoto predpostavljene enakomerne porazdelitve:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Poiščite teoretične frekvence:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Preostali n s bodo enaki:
n s = n*f(x)(x i - x i-1)
| jaz | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3,5E-5 | 0.000199 |
| Skupaj | 1 | 0.0532 |
Zato je kritično območje za to statistiko vedno desno: , če je gostota porazdelitve konstantna na tem segmentu in enaka 0 zunaj njega.
Krivulja enotne porazdelitve je prikazana na sl. 3.13.

riž. 3.13.
Vrednote/ (X) v skrajnostih A in b parcela (a, b) niso navedene, saj je verjetnost zadetka katere koli od teh točk za zvezno naključno spremenljivko X je enako 0.
Matematično pričakovanje naključne spremenljivke x, ki ima enakomerno porazdelitev na odseku [a, d], / « = (a + b)/2. Disperzija se izračuna po formuli D =(b- a) 2/12, torej st = (b - a) / 3,464.
Modeliranje naključnih spremenljivk. Za modeliranje naključne spremenljivke je potrebno poznati njen porazdelitveni zakon. Najpogostejši način za pridobitev zaporedja naključnih števil, porazdeljenih po poljubnem zakonu, je metoda, ki temelji na njihovem oblikovanju iz prvotnega zaporedja naključnih števil, porazdeljenih v intervalu (0; 1) po enotnem zakonu.
enakomerno porazdeljena v intervalu (0; 1) lahko zaporedja naključnih števil dobimo na tri načine:
- po posebej pripravljenih tabelah naključnih števil;
- uporaba fizičnih generatorjev naključnih števil (na primer met kovanca);
- algoritemska metoda.
Za takšna števila naj bo vrednost matematičnega pričakovanja enaka 0,5, varianca pa 1/12. Po potrebi naključno število X je bil v intervalu ( A; b) drugačen od (0; 1), morate uporabiti formulo X \u003d a + (b - a) g, Kje G- naključno število iz intervala (0; 1).
Ker so skoraj vsi modeli implementirani na računalniku, se skoraj vedno za pridobivanje naključnih števil uporablja v računalnik vgrajen algoritemski generator (RNG), čeprav ni problem uporabiti tabel, ki so predhodno pretvorjene v elektronsko obliko. . Upoštevati je treba, da z algoritemsko metodo vedno dobimo psevdonaključna števila, saj je vsako naslednje generirano število odvisno od prejšnjega.
V praksi je vedno treba pridobiti naključna števila, porazdeljena po danem distribucijskem zakonu. Za to se uporabljajo različne metode. Če poznamo analitični izraz za distribucijski zakon F, potem lahko uporabite metoda inverzne funkcije.
Dovolj je, da predvajate naključno število, enakomerno porazdeljeno v intervalu od 0 do 1. Ker funkcija F spreminja tudi v tem intervalu, nato naključno število X lahko določite tako, da vzamete inverzno funkcijo iz grafa ali analitično: x=F"(d). Tukaj G- število, ki ga ustvari RNG v območju od 0 do 1; x t je nastala naključna spremenljivka. Grafično je bistvo metode prikazano na sl. 3.14.

riž. 3.14. Ilustracija metode inverzne funkcije za generiranje naključnih dogodkov X, katerih vrednosti so neprekinjeno porazdeljene. Slika prikazuje grafe gostote verjetnosti in integralne gostote verjetnosti iz X
Razmislite kot primer o eksponentnem zakonu porazdelitve. Porazdelitvena funkcija tega zakona ima obliko F(x) = 1 -exp(-bz). Ker G in F pri tej metodi se predpostavlja, da so podobni in se nahajajo v istem intervalu, nato pa se zamenjajo F za naključno število r imamo G= 1 - exp(-bz). Izražanje želene vrednosti X iz tega izraza (tj. z obračanjem funkcije exp()) dobimo x = -/X? 1p(1 -G). Ker v statističnem smislu (1 - d) in G - potem je ista stvar x \u003d -YX 1p(r).
Algoritmi za modeliranje nekaterih običajnih zakonov porazdelitve zveznih naključnih spremenljivk so podani v tabeli. 3.10.
Na primer, potrebno je simulirati čas nalaganja, ki je porazdeljen po običajnem zakonu. Znano je, da je povprečno trajanje nalaganja 35 minut, standardna deviacija realnega časa od povprečne vrednosti pa 10 minut. Se pravi glede na pogoje naloge t x = 35, z x= 10. Potem bo vrednost naključne spremenljivke izračunana po formuli R= ?g, kjer G. - naključna števila iz RNG v območju, n = 12. Število 12 je izbrano kot dovolj veliko na podlagi osrednjega mejnega izreka teorije verjetnosti (Ljapunovljev izrek): »Za veliko število n naključne spremenljivke X s katerim koli zakonom porazdelitve je njihova vsota naključno število z normalnim zakonom porazdelitve. Nato naključna vrednost X\u003d o (7? - l / 2) + t x = 10(7? -3) + 35.
Tabela 3.10
Algoritmi za modeliranje naključnih spremenljivk
Simulacija naključnega dogodka. Naključni dogodek pomeni, da ima nek dogodek več izidov in kateri od izidov se bo ponovil, določa le njegova verjetnost. To pomeni, da je izid izbran naključno, ob upoštevanju njegove verjetnosti. Recimo, da poznamo verjetnost proizvodnje izdelkov z napako R= 0,1. Pojav tega dogodka lahko simulirate tako, da predvajate enakomerno porazdeljeno naključno število iz območja od 0 do 1 in ugotovite, kateri od dveh intervalov (od 0 do 0,1 ali od 0,1 do 1) je padlo (slika 3.15). Če je število v območju (0; 0,1), je bila izdana napaka, tj. dogodek se je zgodil, sicer pa se dogodek ni zgodil (proizveden je bil kondicioniran izdelek). Z velikim številom poskusov se bo pogostost števil, ki spadajo v interval od 0 do 0,1, približala verjetnosti P= 0,1, pogostost zadetkov števil v intervalu od 0,1 do 1 pa se bo približala P. = 0,9.

riž. 3.15.
Dogodki se imenujejo nezdružljivo, če je verjetnost pojava teh dogodkov hkrati enaka 0. Iz tega sledi, da je skupna verjetnost skupine nekompatibilnih dogodkov enaka 1. Označimo z a r JAZ, a n dogodkov in skozi Р ]9 Р 2 , ..., R str- verjetnost nastopa posameznih dogodkov. Ker sta dogodka nekompatibilna, je vsota verjetnosti njihovega nastanka enaka 1: P x + P 2 + ... +Pn= 1. Spet uporabimo generator naključnih števil, da simuliramo pojav enega od dogodkov, katerega vrednost je prav tako vedno v območju od 0 do 1. Odstavimo segmente na enotskem intervalu P r P v ..., R str. Jasno je, da bo vsota segmentov natanko interval enote. Točka, ki ustreza padlemu številu iz generatorja naključnih števil na tem intervalu, bo kazala na enega od segmentov. V skladu s tem bodo naključna števila pogosteje padla v velike segmente (verjetnost pojava teh dogodkov je večja!), V manjših segmentih - manj pogosto (slika 3.16).
Po potrebi simulacija skupne dogodke morajo biti nezdružljivi. Na primer za simulacijo pojava dogodkov, za katere so podane verjetnosti R(a() = 0,7; P(a 2)= 0,5 in P(a ]9 a 2)= 0,4 definiramo vse možne nekompatibilne izide nastanka dogodkov a d a 2 in njun hkratni nastop:
- 1. Hkratni pojav dveh dogodkov P(b () = P(a L , a 2) = 0,4.
- 2. Pojav dogodka a] P (b 2) \u003d P (a y) - P (a ( , a 2) = 0,7 - 0,4 = 0,3.
- 3. Pojav dogodka a 2 P(b 3) = P (a 2) - P (a g a 2) \u003d 0,5 - 0,4 = 0,1.
- 4. Nenastop na katerem koli dogodku P(b 4) = 1 - (P(b) + P(b 2) + + P(b 3)) =0,2.
Zdaj pa verjetnosti pojava nezdružljivih dogodkov b morajo biti na numerični osi predstavljeni kot segmenti. S sprejemom številk s pomočjo RNG ugotovimo njihovo pripadnost določenemu intervalu in pridobimo izvedbo skupnih dogodkov. A.

riž. 3.16.
Pogosto se pojavlja v praksi sistemi naključnih spremenljivk, torej takih dveh (ali več) različnih naključnih spremenljivk X, pri(in drugi), ki so odvisni drug od drugega. Na primer, če se zgodi dogodek X in vzel neko naključno vrednost, nato dogodek pri zgodi, čeprav po naključju, a ob upoštevanju dejstva, da X je že dobilo neko vrednost.
Na primer, če kot X izpadlo večje število, nato kot pri izpasti mora tudi dovolj veliko število (če je korelacija pozitivna, in obratno, če je negativna). V prometu so takšne odvisnosti precej pogoste. Daljši zastoji so verjetnejši na daljših poteh itd.
Če so naključne spremenljivke odvisne, potem
f(x)=f(x l)f(x 2 x l)f(x 3 x 2 ,x l)- ... -/(xjx, r X„ , ...,x 2 ,x t), Kje x. | x._ v x (- naključne odvisne spremenljivke: osip X. pod pogojem, da so padle x._ (9 x._ ( ,...,*,) - pogojna gostota
verjetnost pojava x.>če izpade x._ (9 ..., x (; f(x) - verjetnost izpada iz vektorja x naključnih odvisnih spremenljivk.
Korelacijski koeficient q kaže, kako tesno so dogodki povezani Hee W.Če je korelacijski koeficient enak eni, potem je odvisnost dogodkov hee woo ena proti ena: ena vrednost X ujema z eno vrednostjo pri(Sl. 3.17, A) . pri q blizu enotnosti, slika, prikazana na sl. 3.17, b, to je ena vrednost X lahko že ustreza več vrednostim Y (natančneje, eni od več vrednosti Y, določenih naključno); torej v tem dogodku X in Y manj povezani, manj odvisni drug od drugega.

riž. 3.17. Vrsta odvisnosti dveh naključnih spremenljivk s pozitivnim korelacijskim koeficientom: a- pri q = 1; b - pri 0 q pri q, blizu O
In končno, ko se korelacijski koeficient nagiba k ničli, pride do situacije, v kateri je katera koli vrednost X lahko ustreza kateri koli vrednosti Y, tj. dogodkom X in Y niso odvisni ali skoraj niso odvisni drug od drugega, ne korelirajo drug z drugim (sl. 3.17, V).
Za primer vzemimo normalno porazdelitev, kot najpogostejšo. Matematično pričakovanje označuje najverjetnejše dogodke, pri čemer je število dogodkov večje, razpored dogodkov pa gostejši. Pozitivna korelacija kaže, da velike naključne spremenljivke X vzrok za ustvarjanje velikih Y. Ničelna in skoraj ničelna korelacija kaže, da je vrednost naključne spremenljivke X nima nobene zveze z določeno vrednostjo naključne spremenljivke Y. Povedano je lahko razumeti, če si najprej zamislimo porazdelitve f(X) in / (Y) ločeno in jih nato povežete v sistem, kot je prikazano na sl. 3.18.
V tem primeru hej Y so porazdeljeni po normalnem zakonu z ustreznimi vrednostmi t x, a in to, A,. Podan je korelacijski koeficient dveh naključnih dogodkov q, tj. naključne spremenljivke X in Y sta odvisna drug od drugega, Y ni povsem naključen.
Potem bo možni algoritem za implementacijo modela naslednji:
1. Igra se šest naključnih števil, enakomerno porazdeljenih na intervalu: b str b:, b i, b 4 , b 5, b 6 ; poiščite njihovo vsoto S:
S = b. Običajno porazdeljeno naključno število l najdemo: po naslednji formuli: x \u003d a (5 - 6) + t x.
- 2. Po formuli m!x = to + qoJo x (x -m x) je matematično pričakovanje t y1x(znak u/x pomeni, da bo y prevzel naključne vrednosti, glede na pogoj, da je * že prevzel nekatere določene vrednosti).
- 3. Po formuli = a d/l -C 2 poiščite standardni odklon a..
4. Igra se 12 naključnih števil r, enakomerno porazdeljenih na intervalu; poiščite njihovo vsoto k:k= Zr. Poiščite normalno porazdeljeno naključno število pri po naslednji formuli: y = °Jk-6) + mr/x.

riž. 3.18.
Modeliranje poteka dogodka. Ko je dogodkov veliko in si sledijo, nastanejo tok. Upoštevajte, da morajo biti dogodki v tem primeru homogeni, to je na nek način podobni drug drugemu. Na primer, pojav voznikov na bencinskih črpalkah, ki želijo natočiti gorivo v svoj avto. To pomeni, da homogeni dogodki tvorijo niz. Predpostavlja se, da je statistična značilnost tega 146
pojavi (intenzivnost toka dogajanja) je podana. Intenzivnost toka dogodkov pove, koliko takih dogodkov se v povprečju zgodi na časovno enoto. Toda kdaj točno se bo zgodil posamezen dogodek, je treba določiti z metodami modeliranja. Pomembno je, da ko ustvarimo npr. 1000 dogodkov v 200 urah, bo njihovo število približno enako povprečni intenzivnosti pojavljanja dogodkov 1000/200 = 5 dogodkov na uro. To je statistična vrednost, ki označuje ta tok kot celoto.
Intenzivnost toka je v nekem smislu matematično pričakovanje števila dogodkov na časovno enoto. Toda v resnici se lahko izkaže, da se bodo v eni uri pojavili 4 dogodki, v drugi pa 6, čeprav v povprečju dobimo 5 dogodkov na uro, tako da ena vrednost ni dovolj za karakterizacijo toka. Druga vrednost, ki označuje, kako velik je razpon dogodkov glede na matematično pričakovanje, je kot prej disperzija. Prav ta vrednost določa naključnost pojava dogodka, šibko predvidljivost trenutka njegovega nastanka.
Naključni tokovi so:
- navaden - verjetnost hkratnega pojava dveh ali več dogodkov je nič;
- stacionarni - pogostost pojavljanja dogodkov X konstantna;
- brez naknadnega učinka - verjetnost pojava naključnega dogodka ni odvisna od trenutka predhodnih dogodkov.
Pri modeliranju QS se v veliki večini primerov upošteva Poissonov (najpreprostejši) tok - navaden pretok brez naknadnega učinka, v katerem je verjetnost prihoda v časovnem intervalu t gladka T zahteve so podane s Poissonovo formulo:
Poissonov tok je lahko stacionaren, če je A.(/) = const(/), ali nestacionaren drugače.
V Poissonovem toku je verjetnost, da se ne zgodi noben dogodek, enaka
Na sl. 3.19 prikazuje odvisnost R od časa. Očitno je, da daljši kot je čas opazovanja, manjša je verjetnost, da do dogodka ne bo prišlo. Še več, višja je vrednost x, bolj strmo gre graf, tj. hitreje pada verjetnost. To ustreza dejstvu, da če je intenzivnost pojavljanja dogodkov velika, potem verjetnost, da se dogodek ne bo zgodil, hitro pada s časom opazovanja.

riž. 3.19.
Verjetnost, da se zgodi vsaj en dogodek P = 1 - shr(-pekel), saj P + P = . Očitno je, da se verjetnost pojava vsaj enega dogodka giblje k enoti s časom, tj. ob ustreznem dolgotrajnem opazovanju se bo dogodek nujno zgodil prej ali slej. V smislu R je enako r, torej izraža / iz definicijske formule R, končno, da določimo intervale med dvema naključnima dogodkoma, imamo
![]()
Kje G- naključno število, enakomerno porazdeljeno od 0 do 1, ki je pridobljeno z uporabo RNG; t- interval med naključnimi dogodki (naključna spremenljivka).
Kot primer upoštevajte tok avtomobilov, ki prihajajo na terminal. Avtomobili prihajajo naključno - povprečno 8 na dan (hitrost pretoka X= 8/24 vozil/h). Moram videti 148
delite ta postopek z T\u003d 100 ur Povprečni časovni interval med avtomobili / \u003d 1 / L. = 24/8 = 3 ure
Na sl. 3.20 prikazuje rezultat simulacije - trenutke v času, ko so avtomobili prišli na terminal. Kot je razvidno, v samo obdobju T = 100 obdelanih terminalov N=33 avto. Če ponovno zaženemo simulacijo, torej n je lahko enako na primer 34, 35 ali 32. Toda v povprečju za TO algoritem teče n bo enako 33,333.
riž. 3.20.
Če je znano, da pretok ni navaden takrat je treba modelirati poleg trenutka nastanka dogodka tudi število dogodkov, ki bi se lahko v tem trenutku pojavili. Na primer, avtomobili pridejo na terminal ob naključnih urah (navaden tok avtomobilov). A hkrati imajo lahko avtomobili različno (naključno) količino tovora. V tem primeru naj bi bil pretok tovora tok izrednih dogodkov.
Razmislimo o nalogi. Določiti je treba čas mirovanja nakladalne opreme na terminalu, če se kontejnerji AUK-1,25 na terminal dostavljajo s tovornjaki. Pretok avtomobilov je podrejen Poissonovemu zakonu, povprečni interval med avtomobili je 0,5 hD = 1/0,5 = 2 avtomobila/uro. Število zabojnikov v avtomobilu se spreminja po običajnem zakonu s povprečno vrednostjo T= 6 in a = 2. V tem primeru je lahko najmanj 2, največ pa 10 posod. Čas razkladanja enega kontejnerja je 4 minute, za tehnološke operacije pa 6 minut. Algoritem za reševanje tega problema, zgrajen na principu zaporednega objavljanja vsake aplikacije, je prikazan na sl. 3.21.
Po vnosu začetnih podatkov se simulacijski cikel zažene, dokler ni dosežen določen čas simulacije. Z uporabo RNG dobimo naključno število, nato določimo časovni interval pred prihodom avtomobila. Nastali interval označimo na časovni osi in simuliramo število kontejnerjev v karoseriji prispelega avtomobila.
Dobljeno številko preverimo za sprejemljiv interval. Nato se izračuna čas razkladanja in sešteje v števcu skupnega časa delovanja nakladalne opreme. Pogoj se preveri: če je interval prihoda avtomobila večji od časa razkladanja, se razlika med njima sešteje v števcu izpadov opreme.

riž. 3.21.
Tipičen primer CMO bi bila nakladalna točka z več stebri, kot je prikazano na sl. 3.22.

riž. 3.22.
Za jasnost procesa modeliranja zgradimo časovni diagram delovanja QS, ki na vsakem ravnilu (časovni osi /) odraža stanje ločenega elementa sistema (slika 3.23). Kolikor različnih objektov v QS (tokovih) je toliko časovnic. V našem primeru jih je 7: tok zahtev, tok čakanja na prvem mestu v čakalni vrsti, tok čakanja na drugem mestu v čakalni vrsti, tok storitve na prvem kanalu, tok storitve v drugem kanalu tok zahtev, ki jih sistem streže, tok zavrnjenih zahtev. Za prikaz postopka zavrnitve storitve predpostavimo, da sta lahko v čakalni vrsti za nakladanje samo dva avtomobila. Če jih je več, se pošljejo na drugo nakladalno mesto.
V prvi vrstici so prikazani simulirani naključni trenutki prejema vlog za vzdrževanje avtomobila. Prva zahteva je sprejeta in ker so kanali trenutno prosti, se nastavi za storitev v prvem kanalu. Aplikacija 1 prenese v linijo prvega kanala. Tudi čas storitve v kanalu je naključen. Na diagramu najdemo trenutek konca storitve, s čimer prestavimo generirani čas storitve od trenutka začetka storitve.
niya in izpustite aplikacijo za vrstico "Served". Aplikacija je do konca šla skozi CMO. Sedaj je po principu sekvenčnega knjiženja nalogov možna tudi simulacija poti drugega naloga.

riž. 3.23.
Če se na neki točki izkaže, da sta oba kanala zasedena, je treba zahtevo postaviti v čakalno vrsto. Na sl. 3.23 je aplikacija 3. Upoštevajte, da v skladu s pogoji naloge v čakalni vrsti za razliko od kanalov aplikacije niso naključno locirane, ampak počakajte, da se eden od kanalov sprosti. Po sprostitvi kanala se zahteva premakne v vrstico ustreznega kanala in tam je organizirano njeno servisiranje.
Če je teža mesta v čakalni vrsti v trenutku, ko prispe naslednja vloga, zasedena, je treba vlogo poslati v vrstico "Zavrnjeno". Na sl. 3.23 je aplikacija 6.
Postopek imitacije vročitve vlog se nadaljuje še nekaj časa T. Daljši kot je ta čas, bolj natančni bodo rezultati simulacije v prihodnosti. V resnici za preproste sisteme izberite T, enako 50-100 ur ali več, čeprav je včasih bolje to vrednost izmeriti s številom obravnavanih aplikacij.
QS bomo analizirali na že obravnavanem primeru.
Najprej morate počakati na stabilno stanje. Prve štiri aplikacije zavržemo kot neznačilne, ki se pojavljajo v procesu vzpostavljanja delovanja sistema (»čas ogrevanja modela«). Izmerimo čas opazovanja, recimo da je v našem primeru T = 5 ur. Število opravljenih zahtevkov izračunamo iz diagrama n o6c , prosti čas in druge vrednosti. Kot rezultat lahko izračunamo kazalnike, ki označujejo kakovost dela QS:
- 1. Verjetnost storitve P \u003d N, / N \u003d 5/7 = 0,714. Za izračun verjetnosti servisiranja aplikacije v sistemu je dovolj, da število aplikacij, ki so bile servisirane v tem času, delimo T(glejte vrstico »Postreženo«), L/o6 na število zahtevkov N, ki so prišli istočasno.
- 2. Prepustnost sistema A \u003d NJT h \u003d 7/5 \u003d 1,4 avto / h. Za izračun prepustnosti sistema je dovolj, da razdelimo število servisiranih zahtev št o6c za nekaj časa T, za katerega je potekala ta storitev.
- 3. Verjetnost neuspeha P \u003d N / N \u003d 3/7 \u003d 0,43. Za izračun verjetnosti zavrnitve storitve za zahtevo zadostuje, da število zahtev delimo n ki jim je bil čas odvzet T(glej vrstico "Zavrnjeno") za število prijav N, ki so želeli služiti v istem času, torej vstopili v sistem. Upoštevajte, da znesek R op + R p (k v teoriji mora biti enako 1. Dejansko se je eksperimentalno izkazalo, da R + R.= 0,714 + 0,43 = 1,144. To netočnost je razloženo z dejstvom, da med opazovanjem T ni bilo zbranih dovolj statističnih podatkov za točen odgovor. Napaka tega kazalnika je zdaj 14%.
- 4. Verjetnost, da je en kanal zaseden P = T r JT H= 0,05/5 = 0,01, kjer je T- čas zasedenosti samo enega kanala (prvega ali drugega). Meritve so podvržene časovnim intervalom, v katerih se zgodijo določeni dogodki. Na primer, na diagramu se takšni segmenti iščejo, ko je zaseden prvi ali drugi kanal. V tem primeru je en tak segment na koncu diagrama z dolžino 0,05 ure.
- 5. Verjetnost, da sta dva kanala zasedena P = T / T = 4,95/5 = 0,99. Na diagramu se iščejo takšni segmenti, med katerimi sta hkrati zasedena prvi in drugi kanal. V tem primeru so štirje takšni segmenti, njihova vsota je 4,95 ure.
- 6. Povprečno število zasedenih kanalov: /V do - 0 P 0 + P X + 2 P, \u003d \u003d 0,01 +2? 0,99 = 1,99. Za izračun, koliko kanalov je v povprečju zasedenih v sistemu, je dovolj, da poznamo delež (verjetnost zasedenosti enega kanala) in pomnožimo s težo tega deleža (en kanal), poznamo delež (verjetnost zasedenosti dveh kanalov). kanalov) in pomnožite s težo tega deleža (dva kanala) itd. Dobljena številka 1,99 pomeni, da je od dveh možnih kanalov v povprečju naloženih 1,99 kanalov. To je visoka stopnja izkoriščenosti 99,5 %, sistem dobro izkorišča vire.
- 7. Verjetnost mirovanja vsaj enega kanala Р*, = Г je preprosta, /Г = = 0,05/5 = 0,01.
- 8. Verjetnost izpada dveh kanalov hkrati: P = = T JT = 0.
- 9. Verjetnost izpada celotnega sistema P * \u003d T / T \u003d 0.
- 10. Povprečno število prijav v čakalni vrsti / V s = 0 P(h + 1 Р in + 2Р b= = 0,34 + 2 0,64 = 1,62 avt. Za določitev povprečnega števila prijav v čakalni vrsti je treba ločeno določiti verjetnost, da bo v čakalni vrsti ena aplikacija P, verjetnost, da bosta v čakalni vrsti dve aplikaciji P 2s in tako naprej ter dodati ponovno z ustreznimi utežmi.
- 11. Verjetnost, da bo v čakalni vrsti ena prijava, P in = = TJTn= 1,7 / 5 \u003d 0,34 (v diagramu so štirje takšni segmenti, skupaj 1,7 ure).
- 12. Verjetnost, da bosta v čakalni vrsti dve vlogi hkrati, R b\u003d Г 2з / Г \u003d 3,2 / 5 \u003d 0,64 (v diagramu so trije takšni segmenti, skupaj 3,25 ure).
- 13. Povprečna čakalna doba za vlogo v čakalni vrsti je Tro = 1,7/4 = = 0,425 ure.Sešteti je potrebno vse časovne intervale, v katerih je bila katera koli vloga v čakalni vrsti in deliti s številom prijav. Na časovnici so 4 takšne aplikacije.
- 14. Povprečni čas storitve za aplikacijo 7' srobsl = 8/5 = 1,6 ure. Seštejte vse časovne intervale, v katerih je bila katera koli aplikacija servisirana v katerem koli kanalu, in delite s številom aplikacij.
- 15. Povprečni čas, ki ga aplikacija porabi v sistemu: T = T +
y y poroka zapel sre. oh
Če natančnost ni zadovoljiva, morate podaljšati čas eksperimenta in s tem izboljšati statistiko. To lahko storite drugače, če preizkus 154 izvedete večkrat
za nekaj časa T in nato povprečite vrednosti teh poskusov, nato pa ponovno preverite rezultate glede na merilo točnosti. Ta postopek je treba ponavljati, dokler ni dosežena želena natančnost.
Analiza rezultatov simulacije
Tabela 3.11
|
Kazalo |
Pomen indikator |
Interesi lastnika CMO |
Interesi strank |
|
Verjetnost storitev |
Verjetnost storitve je nizka, veliko strank zapusti sistem brez storitve. Priporočilo: povečajte verjetnost storitve |
Možnost storitve je nizka, vsaka tretja stranka želi biti postrežena, a je ne morejo postreči Priporočilo: povečajte verjetnost storitve |
|
|
Povprečno število prijav v čakalni vrsti |
Avto je skoraj vedno v vrsti pred servisom Priporočilo: povečajte število mest v čakalni vrsti, povečajte kapaciteto |
||
|
Povečajte prepustnost Povečajte število mest v čakalni vrsti, da ne izgubite potencialnih strank |
Stranke zanima znatno povečanje prepustnosti za zmanjšanje zakasnitve in zmanjšanje napak |
Za odločitev o izvedbi konkretnih aktivnosti je potrebno opraviti analizo občutljivosti modela. Tarča analiza občutljivosti modela je ugotoviti možna odstopanja izhodnih karakteristik zaradi sprememb vhodnih parametrov.
Metode za ocenjevanje občutljivosti simulacijskega modela so podobne metodam za določanje občutljivosti kateregakoli sistema. Če je izhodna značilnost modela R odvisno od parametrov, povezanih s spremenljivkami R =/(p g p 2, p), potem te spremembe
parametri D r.(/ = 1, ..G) povzročiti spremembo AR.

V tem primeru se analiza občutljivosti modela zmanjša na študijo funkcije občutljivosti DR/drugi
Kot primer analize občutljivosti simulacijskega modela razmislimo o vplivu spreminjanja spremenljivih parametrov zanesljivosti vozila na učinkovitost delovanja. Kot ciljno funkcijo uporabimo kazalnik znižanih stroškov З ir. Za analizo občutljivosti uporabljamo podatke o delovanju cestnega vlaka KamAZ-5410 v mestnih razmerah. Meje spreminjanja parametrov R. za določitev občutljivosti modela je dovolj, da jo določimo s strokovnimi sredstvi (tabela 3.12).
Za izvedbo izračunov po modelu je bila izbrana osnovna točka, pri kateri imajo spremenljivi parametri vrednosti, ki ustrezajo standardom. Parameter izpadov med vzdrževanjem in popravili v dnevih je bil nadomeščen s posebnim indikatorjem - izpadi v dneh na tisoč kilometrov n.
Rezultati izračuna so prikazani na sl. 3.24. Osnovna točka je na presečišču vseh krivulj. Prikazano na sl. 3.24 odvisnosti vam omogočajo, da ugotovite stopnjo vpliva vsakega od obravnavanih parametrov na obseg spremembe Z pr. Hkrati pa uporaba naravnih vrednosti analiziranih količin ne omogoča določitve primerjalno stopnjo vpliva vsakega parametra na 3, saj imajo ti parametri različne merske enote. Da bi to preprečili, izberemo obliko interpretacije rezultatov izračuna v relativnih enotah. Da bi to naredili, je treba bazno točko premakniti v izhodišče koordinat, vrednosti spremenljivih parametrov in relativno spremembo izhodnih karakteristik modela pa izraziti v odstotkih. Rezultati izvedenih transformacij so predstavljeni na sl. 3.25.
Tabela 3.12
Vrednote spremenljivi parametri

riž. 3.24.

riž. 3.25. Vpliv relativne spremembe spremenljivih parametrov na stopnjo spremembe
Sprememba variabilnih parametrov glede na osnovno vrednost je prikazana na eni osi. Kot je razvidno iz sl. 3.25, povečanje vrednosti vsakega parametra blizu osnovne točke za 50% vodi do povečanja Z pr za 9% rasti Ts a, za več kot 1,5% C p, za manj kot 0,5% H in zmanjšati 3 za skoraj 4 % povečanja L. Zmanjšaj za 25 % b cr in D rg vodi do povečanja Z pr za več kot 6 %. Zmanjšanje za enako količino parametrov H t0, C tr in C a vodi do zmanjšanja C pr za 0,2, 0,8 oziroma 4,5 %.
Navedene odvisnosti dajejo idejo o vplivu posameznega parametra in se lahko uporabljajo pri načrtovanju delovanja transportnega sistema. Glede na intenzivnost vpliva na Z pr lahko obravnavane parametre razvrstimo v naslednji vrstni red: D, II, L, C 9 N .
'a 7 k.r 7 t.r 7 t.o
Med delovanjem sprememba vrednosti enega indikatorja povzroči spremembo vrednosti drugih indikatorjev, relativna sprememba vsakega od spremenljivih parametrov za isto vrednost pa ima v splošnem neenakomerno fizično osnovo. Relativno spremembo vrednosti spremenljivih parametrov v odstotkih vzdolž abscise je treba nadomestiti s parametrom, ki lahko služi kot enotna mera za oceno stopnje spremembe vsakega parametra. Predpostavimo lahko, da ima v vsakem trenutku delovanja vozila vrednost vsakega parametra enako ekonomsko težo glede na vrednosti drugih spremenljivih parametrov, tj. z ekonomskega vidika je zanesljivost vozila pri vsak trenutek časa ima ravnotežni učinek na vse z njim povezane parametre. Potem bo zahtevani ekonomski ekvivalent čas ali, bolj priročno, leto delovanja.
Na sl. 3.26 prikazuje odvisnosti, zgrajene v skladu z zgornjimi zahtevami. Kot osnovna vrednost Z pr se vzame vrednost v prvem letu obratovanja vozila. Vrednosti spremenljivih parametrov za vsako leto obratovanja so bile določene na podlagi rezultatov opazovanj.

riž. 3.26.
V procesu obratovanja je povečanje W pr v prvih treh letih predvsem posledica povečanja vrednosti H jo , nato pa ima v obravnavanih obratovalnih pogojih glavno vlogo pri zmanjšanju učinkovitosti uporabe TS povečanje C tr Za prepoznavanje vpliva vrednosti L Kp, pri izračunih je bila njegova vrednost enačena s skupno kilometrino vozila od začetka obratovanja. Vrsta funkcije 3 =f(L) kaže, da se intenzivnost zmanjšanja 3 z naraščanjem
itd J v k.r" 7 np J
1 do p znatno zmanjša.
Kot rezultat analize občutljivosti modela je mogoče razumeti, na katere dejavnike je treba vplivati, da se spremeni ciljna funkcija. Za spremembo dejavnikov je potrebno uporabiti nadzorne napore, kar je povezano z ustreznimi stroški. Višina stroškov ne more biti neskončna, kot vsi viri so ti stroški v resnici omejeni. Zato je treba razumeti, v kolikšni meri bo dodeljevanje sredstev učinkovito. Če v večini primerov stroški rastejo linearno z naraščajočim nadzornim delovanjem, potem učinkovitost sistema hitro raste le do določene meje, ko tudi večji stroški ne dajejo več enakega donosa. Na primer, nemogoče je neomejeno povečevati zmogljivost servisnih naprav zaradi prostorskih omejitev ali potencialnega števila oskrbovanih avtomobilov ipd.
Če primerjamo povečanje stroškov in indikator učinkovitosti sistema v istih enotah, potem bo praviloma grafično videti, kot je prikazano na sl. 3.27.

riž. 3.27.
Iz sl. 3.27 je razvidno, da pri dodeljevanju kazalnika cene C na stroškovno enoto Z in cene C na enoto R te krivulje je mogoče dodati. Krivulje se seštevajo, če jih je treba minimizirati ali maksimirati hkrati. Če naj bo ena krivulja maksimizirana, druga pa minimizirana, je treba njuno razliko najti, na primer s točkami. Potem bo dobljena krivulja (slika 3.28), ki upošteva tako učinek upravljanja kot stroške tega, imela ekstrem. Vrednost parametra /?, ki podaja ekstrem funkcije, je rešitev sinteznega problema.

riž. 3.28.
do mimo.
Onkraj upravljanja R in indikator R sistemi so moteni. Motnja D= (d v d r...) je vhodna akcija, ki za razliko od krmilnega parametra ni odvisna od volje lastnika sistema (slika 3.29). Na primer, nizke temperature zunaj, konkurenca, žal, zmanjšajo pretok strank; okvare strojne opreme zmanjšajo zmogljivost sistema. Lastnik sistema teh vrednosti ne more upravljati neposredno. Običajno ogorčenje deluje "vkljub" lastniku in zmanjša učinek R od prizadevanj vodstva R. To pa zato, ker je sistem v splošnem ustvarjen za doseganje ciljev, ki so v naravi sami po sebi nedosegljivi. Človek, ki organizira sistem, vedno upa, da bo z njim dosegel nek cilj. R. To je tisto, za kar se trudi. R. V tem kontekstu lahko rečemo, da je sistem organizacija naravnih komponent, ki so na voljo človeku, ki jih preučuje, da bi dosegel nov cilj, prej nedosegljiv na druge načine.

riž. 3.29.
Če odstranimo odvisnost indikatorja R od uprave Rše enkrat, vendar pod pogoji motnje D, potem se bo morda narava krivulje spremenila. Najverjetneje bo indikator nižji za enake kontrolne vrednosti, saj je motnja negativna, kar zmanjšuje zmogljivost sistema. Sistem, prepuščen sam sebi, brez naporov menedžerske narave, preneha zagotavljati cilj, za katerega je bil ustvarjen. Če, kot prej, zgradimo odvisnost stroškov, jo povežemo z odvisnostjo indikatorja od kontrolnega parametra, potem se bo najdena ekstremna točka premaknila (slika 3.30) v primerjavi s primerom "motnje = 0" (glej sliko 3.28). Če se motnja ponovno poveča, se krivulje spremenijo in posledično se položaj ekstremne točke ponovno spremeni.
Graf na sl. 3.30 se nanaša na kazalnik P, upravljanje (vir) R in ogorčenje D v kompleksnih sistemih nakazujejo, kako najbolje ravnati vodji (organizaciji), ki v sistemu sprejema odločitve. Če je nadzorni ukrep manjši od optimalnega, se skupni učinek zmanjša in nastane situacija izgubljenega dobička. Če je nadzorni ukrep večji od optimalnega, se bo tudi učinek zmanjšal, saj se plača čakalna vrsta
Vsako povečanje naporov pri nadzoru bo moralo biti večje od tistega, kar dobite kot rezultat uporabe sistema.

riž. 3.30.
Simulacijski model sistema za realno uporabo mora biti implementiran na računalniku. To lahko ustvarite z naslednjimi orodji:
- univerzalni uporabniški program vrsta matematičnega (MATLAB) ali procesorja za preglednice (Excel) ali DBMS (Access, FoxPro), ki omogoča izdelavo le relativno enostavnega modela in zahteva vsaj začetno znanje programiranja;
- univerzalni programski jezik(C++, Java, Basic itd.), ki vam omogoča ustvarjanje modela katere koli kompleksnosti; vendar je to zelo dolgotrajen proces, ki zahteva pisanje velike količine programske kode in dolgotrajno odpravljanje napak;
- specializiran simulacijski jezik, ki ima že pripravljene predloge in orodja za vizualno programiranje, namenjena hitremu ustvarjanju osnove modela. Eden najbolj znanih je UML (Unified Modeling Language);
- simulacijski programi, ki so najbolj priljubljen način ustvarjanja simulacijskih modelov. Omogočajo vizualno ustvarjanje modela, le v najtežjih primerih, zatekanje k ročnemu pisanju programske kode za postopke in funkcije.
Simulacijske programe delimo na dve vrsti:
- Vsestranski simulacijski paketi so zasnovani za ustvarjanje različnih modelov in vsebujejo nabor funkcij, ki se lahko uporabljajo za simulacijo tipičnih procesov v sistemih različnih namenov. Priljubljeni paketi te vrste so Arena (razvijalec Rockwell Automation 1 ", ZDA), Extendsim (razvijalec Imagine That Ink., ZDA), AnyLogic (razvijalec XJ Technologies, Rusija) in številni drugi. Skoraj vsi univerzalni paketi imajo specializirane različice za modeliranje predmetov specifičnih razredov.
- Domensko specifični simulacijski paketi služijo za modeliranje določenih vrst predmetov in imajo za to specializirana orodja v obliki predlog, čarovnikov za vizualno oblikovanje modela iz že pripravljenih modulov itd.
- Dve naključni števili seveda ne moreta biti enolično odvisni drug od drugega, sl. 3.17, a je podan zaradi jasnosti koncepta korelacije. 144
- Tehnična in ekonomska analiza pri preučevanju zanesljivosti KamAZ-5410 / Yu. G. Kotikov, I. M. Blyankinshtein, A. E. Gorev, A. N. Borisenko; LISI. L.:, 1983. 12 str.-odd. v TsBNTI Minavtotrans RSFSR, št. 135at-D83.
- http://www.rockwellautomation.com.
- http://www.cxtcndsiin.com.
- http://www.xjtek.com.
Kot smo že omenili, primeri verjetnostnih porazdelitev zvezna naključna spremenljivka X so:
- enotna verjetnostna porazdelitev zvezne naključne spremenljivke;
- eksponentna verjetnostna porazdelitev zvezne naključne spremenljivke;
- normalna porazdelitev verjetnosti zvezne naključne spremenljivke.
Podajamo koncept enakomernih in eksponentnih zakonov porazdelitve, verjetnostne formule in numerične značilnosti obravnavanih funkcij.
| Kazalo | Zakon naključne porazdelitve | Eksponentni zakon porazdelitve |
|---|---|---|
| Opredelitev | Uniforma se imenuje verjetnostna porazdelitev zvezne naključne spremenljivke X, katere gostota ostaja konstantna na intervalu in ima obliko | Eksponentna (eksponentna) se imenuje verjetnostna porazdelitev zvezne naključne spremenljivke X, ki je opisana z gostoto v obliki |
 kjer je λ konstantna pozitivna vrednost |
||
| distribucijska funkcija |  |
|
| Verjetnost zadeti interval |  |
|
| Pričakovana vrednost | ||
| Razpršenost |  |
|
| Standardni odklon |  |
Primeri reševanja problemov na temo "Enorni in eksponentni zakoni porazdelitve"
Naloga 1.
Avtobusi vozijo strogo po voznem redu. Interval gibanja 7 min. Ugotovite: (a) verjetnost, da bo potnik, ki prihaja na postajo, čakal na naslednji avtobus manj kot dve minuti; b) verjetnost, da bo potnik, ki se bliža postajališču, čakal na naslednji avtobus najmanj tri minute; c) matematično pričakovanje in standardni odklon slučajne spremenljivke X - potnikova čakalna doba.
rešitev. 1. Po pogoju problema je zvezna slučajna spremenljivka X=(čakalni čas potnika) enakomerno porazdeljena med prihodom dveh avtobusov. Dolžina intervala porazdelitve naključne spremenljivke X je enaka b-a=7, kjer je a=0, b=7.
2. Čakalni čas bo krajši od dveh minut, če naključna vrednost X pade v interval (5;7). Verjetnost padca v dani interval se ugotovi po formuli: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(5< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. Čakalna doba bo vsaj tri minute (to je od tri do sedem minut), če naključna vrednost X pade v interval (0; 4). Verjetnost padca v dani interval se ugotovi po formuli: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(0< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Matematično pričakovanje zvezne, enakomerno porazdeljene naključne spremenljivke X - čakalne dobe potnika, najdemo po formuli: M(X)=(a+b)/2. M (X) \u003d (0 + 7) / 2 \u003d 7/2 \u003d 3,5.
5. Standardni odklon zvezne, enakomerno porazdeljene naključne spremenljivke X - čakalne dobe potnika, najdemo po formuli: σ(X)=√D=(b-a)/2√3. σ(X)=(7-0)/2√3=7/2√3≈2,02.
Naloga 2.
Eksponentna porazdelitev je podana za x ≥ 0 z gostoto f(x) = 5e – 5x. Zahtevano: a) napišite izraz za distribucijsko funkcijo; b) poiščite verjetnost, da X kot rezultat testa pade v interval (1; 4); c) ugotovite verjetnost, da bo kot rezultat testa X ≥ 2; d) izračunajte M(X), D(X), σ(X).
rešitev. 1. Ker je pod pogojem eksponentna porazdelitev , potem iz formule za verjetnostno gostoto porazdelitve naključne spremenljivke X dobimo λ = 5. Potem bo porazdelitvena funkcija videti takole:
2. Verjetnost, da kot rezultat testa X pade v interval (1; 4), bo ugotovljena s formulo:
P(a< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. Verjetnost, da bo rezultat testa X ≥ 2 najden po formuli: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
Р(Х≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Za eksponentno porazdelitev ugotovimo:
- matematično pričakovanje po formuli M(X) =1/λ = 1/5 = 0,2;
- disperzija po formuli D (X) \u003d 1 / λ 2 \u003d 1/25 \u003d 0,04;
- standardni odklon po formuli σ(X) = 1/λ = 1/5 = 1,2.
Porazdelitvena funkcija bo v tem primeru glede na (5.7) imela obliko:
kjer je: m matematično pričakovanje, s standardni odklon.
Normalna porazdelitev se imenuje tudi Gaussova po nemškem matematiku Gaussu. Dejstvo, da ima slučajna spremenljivka normalno porazdelitev s parametri: m,, je označeno kot sledi: N (m, s), kjer je: m =a =M ;
Precej pogosto je v formulah matematično pričakovanje označeno z A . Če je naključna spremenljivka porazdeljena po zakonu N(0,1), se imenuje normalizirana ali standardizirana normalna vrednost. Porazdelitvena funkcija zanj ima obliko:
|
|
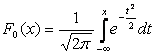 .
.Graf gostote normalne porazdelitve, ki ga imenujemo normalna krivulja ali Gaussova krivulja, je prikazan na sliki 5.4.

riž. 5.4. Normalna gostota porazdelitve
Na primeru je obravnavano določanje numeričnih značilnosti naključne spremenljivke z njeno gostoto.
Primer 6.
Zvezna naključna spremenljivka je podana z gostoto porazdelitve: ![]() .
.
Določite vrsto porazdelitve, poiščite matematično pričakovanje M(X) in varianco D(X).
Če primerjamo podano gostoto porazdelitve z (5.16), lahko sklepamo, da je podan normalni zakon porazdelitve z m =4. Zato je matematično pričakovanje M(X)=4, varianca D(X)=9.
Standardni odklon s=3.
Laplaceova funkcija, ki ima obliko:
|
|
 ,
,je povezana z normalno porazdelitveno funkcijo (5.17) z razmerjem:
F 0 (x) \u003d F (x) + 0,5.
Laplaceova funkcija je čudna.
Ф(-x)=-Ф(x).
Vrednosti Laplaceove funkcije Ф(х) so prikazane v tabeli in vzete iz tabele glede na vrednost x (glej Dodatek 1).
Normalna porazdelitev zvezne naključne spremenljivke ima pomembno vlogo v teoriji verjetnosti in pri opisovanju realnosti, zelo razširjena je v naključnih naravnih pojavih. V praksi zelo pogosto obstajajo naključne spremenljivke, ki nastanejo ravno kot rezultat seštevanja številnih naključnih členov. Predvsem analiza merskih napak pokaže, da so le-te seštevek različnih vrst napak. Praksa kaže, da je verjetnostna porazdelitev merilnih napak blizu normalnemu zakonu.
Z uporabo Laplaceove funkcije je mogoče rešiti probleme izračuna verjetnosti padca v dani interval in danega odstopanja normalne naključne spremenljivke.


