YouTube enciclopédico
1 / 1
✪ Norma vetorial. Parte 4
Legendas
Definição
Seja K o campo principal (geralmente k = R ou k = C ) e é o espaço linear de todas as matrizes com m linhas e n colunas, constituídas por elementos de K . Uma norma é dada no espaço de matrizes se cada matriz estiver associada a um número real não negativo ‖ A ‖ (\displaystyle \|A\|), chamada de sua norma, de modo que
No caso de matrizes quadradas (ou seja, m = n), as matrizes podem ser multiplicadas sem sair do espaço e, portanto, as normas nesses espaços geralmente também satisfazem a propriedade submultiplicatividade :
A submultiplicatividade também pode ser realizada para as normas de matrizes não quadradas, mas definidas para vários tamanhos necessários ao mesmo tempo. Ou seja, se A é uma matriz ℓ × m, e B é a matriz m × n, então A B- matriz ℓ × n .
Normas do operador
Uma importante classe de normas matriciais são normas do operador, também conhecido como subordinados ou induzido . A norma do operador é construída exclusivamente de acordo com as duas normas definidas em e , com base no fato de que qualquer matriz m × né representado por um operador linear de Kn (\displaystyle K^(n)) dentro Km (\displaystyle K^(m)). Especificamente,
‖ A ‖ = sup ( ‖ A x ‖ : x ∈ K n , ‖ x ‖ = 1 ) = sup ( ‖ A x ‖ ‖ x ‖ : x ∈ K n , x ≠ 0). (\displaystyle (\begin(aligned)\|A\|&=\sup\(\|Ax\|:x\in K^(n),\ \|x\|=1\)\\&=\ sup \left\((\frac (\|Ax\|)(\|x\|)):x\in K^(n),\ x\neq 0\right\).\end(aligned)))Sob a condição de que as normas em espaços vetoriais sejam consistentemente especificadas, tal norma é submultiplicativa (consulte Recursos).
Exemplos de normas do operador
Propriedades da norma espectral:
- A norma espectral de um operador é igual ao valor singular máximo desse operador.
- A norma espectral de um operador normal é igual ao valor absoluto do autovalor máximo do módulo deste operador.
- A norma espectral não muda quando uma matriz é multiplicada por uma matriz ortogonal (unitária).
Normas não operadoras de matrizes
Existem normas matriciais que não são normas operadoras. O conceito de normas não-operadoras de matrizes foi introduzido por Yu. I. Lyubich e estudado por G. R. Belitsky.
Um exemplo de uma norma não-operadora
Por exemplo, considere duas normas de operadores diferentes ‖ A ‖ 1 (\displaystyle \|A\|_(1)) e ‖ A ‖ 2 (\displaystyle \|A\|_(2)), como normas de linha e coluna. Formando uma nova norma ‖ A ‖ = m a x (‖ A ‖ 1 , ‖ A ‖ 2) (\displaystyle \|A\|=max(\|A\|_(1),\|A\|_(2))). A nova norma tem propriedade anular ‖ A B ‖ ≤ ‖ A ‖ ‖ B ‖ (\displaystyle \|AB\|\leq \|A\|\|B\|), preserva a unidade ‖ I ‖ = 1 (\displaystyle \|I\|=1) e não é operadora.
Exemplos de normas
Vetor p (\displaystyle p)-norma
Pode ser considerado m × n (\displaystyle m\vezes n) matriz como um vetor de tamanho m n (\displaystyle mn) e use normas vetoriais padrão:
‖ A ‖ p = ‖ v e c (A) ‖ p = (∑ i = 1 m ∑ j = 1 n | a i j | p) 1 / p (\displaystyle \|A\|_(p)=\|\mathrm ( vec) (A)\|_(p)=\esquerda(\soma _(i=1)^(m)\soma _(j=1)^(n)|a_(ij)|^(p)\ direita)^(1/p))norma de Frobenius
norma de Frobenius, ou norma euclidianaé um caso especial da norma p para p = 2 : ‖ A ‖ F = ∑ i = 1 m ∑ j = 1 n a i j 2 (\displaystyle \|A\|_(F)=(\sqrt (\sum _(i=1)^(m)\sum _(j =1)^(n)a_(ij)^(2)))).
A norma Frobenius é fácil de calcular (em comparação com, por exemplo, a norma espectral). Tem as seguintes propriedades:
‖ A x ‖ 2 2 = ∑ i = 1 m | ∑ j = 1 n a i j x j | 2 ≤ ∑ i = 1 m (∑ j = 1 n | a i j | 2 ∑ j = 1 n | x j | 2) = ∑ j = 1 n | x j | 2 ‖ A ‖ F 2 = ‖ A ‖ F 2 ‖ x ‖ 2 2 . (\displaystyle \|Ax\|_(2)^(2)=\sum _(i=1)^(m)\left|\sum _(j=1)^(n)a_(ij)x_( j)\direita|^(2)\leq \soma _(i=1)^(m)\esquerda(\soma _(j=1)^(n)|a_(ij)|^(2)\soma _(j=1)^(n)|x_(j)|^(2)\direita)=\soma _(j=1)^(n)|x_(j)|^(2)\|A\ |_(F)^(2)=\|A\|_(F)^(2)\|x\|_(2)^(2).)- Submultiplicatividade: ‖ A B ‖ F ≤ ‖ A ‖ F ‖ B ‖ F (\displaystyle \|AB\|_(F)\leq \|A\|_(F)\|B\|_(F)), Porque ‖ A B ‖ F 2 = ∑ i , j | ∑ k a i k b k j | 2 ≤ ∑ i , j (∑ k | a i k | | b k j |) 2 ≤ ∑ i , j (∑ k | a i k | 2 ∑ k | b k j | 2) = ∑ i , k | ai k | 2 ∑ k , j | b k j | 2 = ‖ A ‖ F 2 ‖ B ‖ F 2 (\displaystyle \|AB\|_(F)^(2)=\sum _(i,j)\left|\sum _(k)a_(ik) b_(kj)\direita|^(2)\leq \soma _(i,j)\esquerda(\soma _(k)|a_(ik)||b_(kj)|\direita)^(2)\ leq \sum _(i,j)\left(\sum _(k)|a_(ik)|^(2)\sum _(k)|b_(kj)|^(2)\right)=\sum _(i,k)|a_(ik)|^(2)\soma _(k,j)|b_(kj)|^(2)=\|A\|_(F)^(2)\| B\|_(F)^(2)).
- ‖ A ‖ F 2 = t r A ∗ A = t r A A ∗ (\displaystyle \|A\|_(F)^(2)=\mathop (\rm (tr)) A^(*)A=\ mathop (\rm (tr)) AA^(*)), Onde t r A (\displaystyle \mathop (\rm (tr)) A)- rastreamento de matriz A (\displaystyle A), A ∗ (\displaystyle A^(*))é uma matriz conjugada hermitiana.
- ‖ A ‖ F 2 = ρ 1 2 + ρ 2 2 + ⋯ + ρ n 2 (\displaystyle \|A\|_(F)^(2)=\rho _(1)^(2)+\rho _ (2)^(2)+\pontos +\rho _(n)^(2)), Onde ρ 1 , ρ 2 , … , ρ n (\displaystyle \rho _(1),\rho _(2),\dots ,\rho _(n))- valores singulares da matriz A (\displaystyle A).
- ‖ A ‖ F (\displaystyle \|A\|_(F)) não muda ao multiplicar uma matriz A (\displaystyle A) esquerda ou direita em matrizes ortogonais (unitárias).
Módulo máximo
A norma do módulo máximo é outro caso especial da norma p para p = ∞ .
‖ A ‖ max = max ( | a i j | ) . (\displaystyle \|A\|_(\text(max))=\max\(|a_(ij)|\).)Norma Shatten
Consistência das normas de matriz e vetor
Norma Matriz ‖ ⋅ ‖ a b (\displaystyle \|\cdot \|_(ab)) no K m × n (\displaystyle K^(m\vezes n)) chamado concordou com as normas ‖ ⋅ ‖ a (\displaystyle \|\cdot \|_(a)) no Kn (\displaystyle K^(n)) e ‖ ⋅ ‖ b (\displaystyle \|\cdot \|_(b)) no Km (\displaystyle K^(m)), E se:
‖ A x ‖ b ≤ ‖ A ‖ a b ‖ x ‖ a (\displaystyle \|Ax\|_(b)\leq \|A\|_(ab)\|x\|_(a))para qualquer A ∈ K m × n , x ∈ K n (\displaystyle A\in K^(m\vezes n),x\in K^(n)). Por construção, a norma do operador é consistente com a norma do vetor original.
Exemplos de normas matriciais consistentes, mas não subordinadas:
Equivalência de normas
Todas as normas no espaço K m × n (\displaystyle K^(m\vezes n)) são equivalentes, ou seja, para quaisquer duas normas ‖ . α (\displaystyle \|.\|_(\alpha )) e ‖ . ‖ β (\displaystyle \|.\|_(\beta )) e para qualquer matriz A ∈ K m × n (\displaystyle A\in K^(m\vezes n)) a dupla desigualdade é verdadeira.
» Lição 12. Classificação da matriz. Cálculo da classificação da matriz. Norma matricial
Lição número 12. Classificação da matriz. Cálculo da classificação da matriz. Norma matricial.
Se todos os menores de matrizUMAordemksão iguais a zero, então todos os menores de ordem k + 1, se existirem, também são iguais a zero.
Classificação da matriz UMA
é a maior ordem dos menores da matriz UMA
, diferente de zero.
A classificação máxima pode ser igual ao número mínimo do número de linhas ou colunas da matriz, ou seja, se a matriz tiver um tamanho de 4x5, a classificação máxima será 4.
O posto mínimo de uma matriz é 1, a menos que você esteja lidando com uma matriz zero, onde o posto é sempre zero.
O posto de uma matriz quadrada não degenerada de ordem n é igual a n, pois seu determinante é um menor de ordem n e a matriz não degenerada é diferente de zero.
A transposição de uma matriz não altera seu posto.
Seja o posto da matriz . Então qualquer menor de ordem , diferente de zero, é chamado menor básico.
Exemplo. Dada uma matriz A. 
O determinante da matriz é zero.
Menor de segunda ordem ![]() . Portanto, r(A)=2 e o menor é básico.
. Portanto, r(A)=2 e o menor é básico.
Um menor básico também é um menor ![]() .
.
Menor ![]() , Porque =0, portanto não será básico.
, Porque =0, portanto não será básico.
Exercício: verifique independentemente quais outros menores de segunda ordem serão básicos e quais não serão.
Encontrar o posto de uma matriz calculando todos os seus menores requer muito trabalho computacional. (O leitor pode verificar que existem 36 menores de segunda ordem em uma matriz quadrada de quarta ordem.) Portanto, um algoritmo diferente é usado para encontrar o posto. Para descrevê-lo, algumas informações adicionais são necessárias.
Chamamos as seguintes operações sobre eles transformações elementares de matrizes:
1) permutação de linhas ou colunas;
2) multiplicar uma linha ou coluna por um número diferente de zero;
3) adicionar a uma das linhas outra linha, multiplicada por um número, ou adicionar a uma das colunas de outra coluna, multiplicada por um número.
Sob transformações elementares, o posto da matriz não muda.
Algoritmo para calcular o posto de uma matrizé semelhante ao algoritmo de cálculo do determinante e reside no fato de que, com a ajuda de transformações elementares, a matriz é reduzida a uma forma simples para a qual não é difícil encontrar a classificação. Como o posto não muda a cada transformação, calculando o posto da matriz transformada, encontramos o posto da matriz original.
Seja necessário calcular o posto da matriz de dimensões mxn.
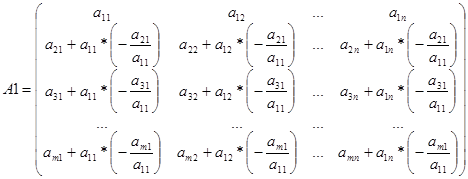
Como resultado dos cálculos, a matriz A1 tem a forma 

Se todas as linhas, a partir da terceira, forem zero, então ![]() , desde menor
, desde menor ![]() . Caso contrário, permutando linhas e colunas com números maiores que dois, conseguimos que o terceiro elemento da terceira linha seja diferente de zero. Além disso, adicionando a terceira linha, multiplicada pelos números correspondentes, às linhas com números grandes, obtemos zeros na terceira coluna, começando no quarto elemento e assim por diante.
. Caso contrário, permutando linhas e colunas com números maiores que dois, conseguimos que o terceiro elemento da terceira linha seja diferente de zero. Além disso, adicionando a terceira linha, multiplicada pelos números correspondentes, às linhas com números grandes, obtemos zeros na terceira coluna, começando no quarto elemento e assim por diante.
Em algum momento, chegaremos a uma matriz na qual todas as linhas, começando de (r + 1) th, são iguais a zero (ou ausentes em ), e o menor nas primeiras linhas e primeiras colunas é o determinante de um triângulo matriz com elementos diferentes de zero na diagonal. A classificação de tal matriz é . Portanto, Rang(A)=r.
No algoritmo proposto para encontrar o posto de uma matriz, todos os cálculos devem ser feitos sem arredondamento. Uma mudança arbitrariamente pequena em pelo menos um dos elementos das matrizes intermediárias pode levar ao fato de que a resposta resultante será diferente do posto da matriz original em várias unidades.
Se os elementos da matriz original forem inteiros, é conveniente realizar cálculos sem usar frações. Portanto, em cada etapa, é aconselhável multiplicar as strings por números que não apareçam frações nos cálculos.
No trabalho de laboratório e prático, consideraremos um exemplo de como encontrar o posto de uma matriz.
ENCONTRANDO ALGORITMO REGULAMENTO DA MATRIZ
.
Existem apenas três normas da matriz.
Norma da Primeira Matriz= o máximo dos números obtidos pela soma de todos os elementos de cada coluna, tomado módulo.
Exemplo: seja dada uma matriz 3x2 A (Fig. 10). A primeira coluna contém os elementos: 8, 3, 8. Todos os elementos são positivos. Vamos encontrar a soma deles: 8+3+8=19. A segunda coluna contém os elementos: 8, -2, -8. Dois elementos são negativos, portanto, ao somar esses números, é necessário substituir o módulo desses números (ou seja, sem os sinais de menos). Vamos encontrar a soma deles: 8+2+8=18. O máximo desses dois números é 19. Portanto, a primeira norma da matriz é 19.

Figura 10.
Norma da Segunda Matrizé a raiz quadrada da soma dos quadrados de todos os elementos da matriz. E isso significa que elevamos ao quadrado todos os elementos da matriz, depois somamos os valores resultantes e extraímos a raiz quadrada do resultado.
Em nosso caso, a norma 2 da matriz acabou sendo igual à raiz quadrada de 269. No diagrama, tirei aproximadamente a raiz quadrada de 269 e o resultado foi aproximadamente 16,401. Embora seja mais correto não extrair a raiz. 
Terceira Matriz de Normasé o máximo dos números obtidos somando todos os elementos de cada linha, tomado módulo.
No nosso exemplo: a primeira linha contém os elementos: 8, 8. Todos os elementos são positivos. Vamos encontrar a soma deles: 8+8=16. A segunda linha contém os elementos: 3, -2. Um dos elementos é negativo, portanto, ao somar esses números, você deve substituir o módulo desse número. Vamos encontrar a soma deles: 3+2=5. A terceira linha contém os elementos 8 e -8. Um dos elementos é negativo, portanto, ao somar esses números, você deve substituir o módulo desse número. Vamos encontrar a soma deles: 8+8=16. O máximo desses três números é 16. Portanto, a terceira norma da matriz é 16. 
Compilado por: Saliy N.A.
Norma matricial chamamos o número real atribuído a esta matriz ||A|| tal que, como um número real, é atribuído a cada matriz do espaço n-dimensional e satisfaz 4 axiomas:
1. ||A||³0 e ||A||=0 somente se A for uma matriz nula;
2. ||αA||=|α|·||A||, onde a R;
3. ||A+B||£||A||+||B||;
4. ||A·B||£||A||·||B||. (propriedade da multiplicatividade)
A norma da matriz pode ser inserida de várias maneiras. A matriz A pode ser vista como n 2 - vetor dimensional.
Esta norma é chamada de norma euclidiana de uma matriz.
Se para qualquer matriz quadrada A e qualquer vetor x cuja dimensão é igual à ordem da matriz, a desigualdade ||Ax||£||A||·||x||
então dizemos que a norma da matriz A é consistente com a norma do vetor. Observe que a norma do vetor está à esquerda na última condição (Ax é um vetor).
Várias normas de matriz são consistentes com uma determinada norma de vetor. Vamos escolher o menor entre eles. Tal será
Esta norma de matriz está subordinada à norma de vetor dada. A existência de um máximo nesta expressão decorre da continuidade da norma, pois sempre existe um vetor x -> ||x||=1 e ||Ax||=||A||.
Mostremos que xentão a norma N(A) não está sujeita a nenhuma norma vetorial. As normas matriciais subordinadas às normas vetoriais introduzidas anteriormente são expressas da seguinte forma:
1. ||A|| ¥ = |a ij | (norma máxima)
2. ||A|| 1 = |a ij | (soma-norma)
3. ||A|| 2 = , (norma espectral)
onde s 1 é o maior autovalor da matriz simétrica A¢A, que é o produto das matrizes transposta e original. Se a matriz A¢A for simétrica, então todos os seus autovalores são reais e positivos. O número l é um autovalor, e um vetor diferente de zero x é um autovetor da matriz A (se eles estiverem relacionados pela relação Ax=lx). Se a própria matriz A é simétrica, A¢ = A, então A¢A = A 2 e então s 1 = , onde é o autovalor da matriz A de maior valor absoluto, portanto, neste caso temos = .
Os autovalores da matriz não excedem nenhuma de suas normas acordadas. Normalizando a relação definindo os autovalores, obtemos ||λx||=||Ax||, |λ|·||x||=||Ax||£||A||·||x||, | λ| £||A||
Como ||A|| 2 £||A|| e , onde a norma euclidiana pode ser calculada de forma simples, ao invés da norma espectral pode ser utilizada nas estimativas a norma euclidiana da matriz.
30. Condicionalidade de sistemas de equações. fator de condicionamento .
Grau de condicionalidade- influência da decisão nos dados iniciais. ax = b: vetor b corresponde decisão x. Deixar b vai mudar por . Então o vetor b+ corresponderá à nova solução x+ : A(x+ ) = b+. Como o sistema é linear, então Ax+A = b+, então UMA = ; = ; = ; b = Machado; = então; * , onde é o erro relativo da perturbação da solução, – fator de condicionamentocond(A) (quantas vezes o erro da solução pode aumentar), é a perturbação relativa do vetor b. cond(A) = ; cond(A)* Propriedades dos coeficientes: depende da escolha da norma da matriz; cond( = cond(A); multiplicar uma matriz por um número não afeta o fator de condição. Quanto maior o coeficiente, mais forte o erro nos dados iniciais afeta a solução do SLAE. O número da condição não pode ser menor que 1.
31. Método de varredura para resolver sistemas de equações algébricas lineares.
Muitas vezes há a necessidade de resolver sistemas cujas matrizes, sendo fracamente preenchidas, ou seja, contendo muitos elementos diferentes de zero. As matrizes de tais sistemas geralmente possuem uma certa estrutura, entre as quais existem sistemas com matrizes de estrutura de banda, ou seja, neles, os elementos diferentes de zero estão localizados na diagonal principal e em várias diagonais secundárias. Para resolver sistemas com matrizes de bandas, o método Gaussiano pode ser transformado em métodos mais eficientes. Consideremos o caso mais simples de sistemas de fita, ao qual, como veremos adiante, a solução de problemas de discretização para problemas de valor de contorno para equações diferenciais é reduzida pelos métodos de diferenças finitas, elementos finitos, etc. Uma matriz de três diagonais é uma matriz que possui elementos diferentes de zero apenas na diagonal principal e adjacente a ela:
A matriz de três diagonais de elementos diferentes de zero tem um total de (3n-2).
Renomeie os coeficientes da matriz:
Então, na notação componente por componente, o sistema pode ser representado como:
A i * x i-1 + b i * x i + c i * x i+1 = d i , i=1, 2,…, n; (7)
a1 =0, cn =0. (oito)
A estrutura do sistema assume a relação apenas entre incógnitas vizinhas:
x i \u003d x i * x i +1 + h i (9)
x i -1 =x i -1* x i + h i -1 e substitua em (7):
A i (x i-1* x i + h i-1)+ b i * x i + c i * x i+1 = d i
(a i * x i-1 + b i)x i = –c i * x i+1 +d i –a i * h i-1
Comparando a expressão resultante com a representação (7), obtemos:
As fórmulas (10) representam relações recursivas para calcular os coeficientes de varredura. Eles exigem que os valores iniciais sejam especificados. De acordo com a primeira condição (8) para i =1 temos a 1 =0, o que significa
Além disso, os coeficientes de varredura restantes são calculados e armazenados de acordo com as fórmulas (10) para i=2,3,…, n e para i=n, levando em consideração a segunda condição (8), obtemos x n =0 . Portanto, de acordo com a fórmula (9) x n = h n .
Depois disso, de acordo com a fórmula (9), as incógnitas x n -1 , x n -2 , …, x 1 são encontradas sequencialmente. Esta etapa do cálculo é chamada de operação reversa, enquanto o cálculo dos coeficientes de varredura é chamado de varredura direta.
Para a aplicação bem-sucedida do método de varredura, é necessário que no processo de cálculos não ocorram situações com divisão por zero, e com uma grande dimensionalidade dos sistemas não haja um aumento rápido dos erros de arredondamento. Vamos chamar a corrida correto, se o denominador dos coeficientes de varredura (10) não desaparecer, e sustentável, se ½ x i ½<1 при всех i=1,2,…, n. Достаточные условия корректности и устойчивости прогонки, которые во многих приложениях выполняются, определяются теоремой.
Teorema. Sejam os coeficientes a i e c i da equação (7) para i=2,3,..., n-1 diferentes de zero e sejam
½b i ½>½a i ½+½c i ½ para i=1, 2,..., n. (onze)
Então a varredura definida pelas fórmulas (10), (9) é correta e estável.


