Com a ajuda de que muitos processos reais são modelados. E o exemplo mais comum é o horário do transporte público. Suponha que um ônibus (trólebus / bonde) anda em intervalos de 10 minutos, e em um tempo aleatório você para. Qual é a probabilidade de que o ônibus chegue em 1 minuto? Obviamente 1/10. E a probabilidade de você ter que esperar de 4 a 5 minutos? Também . Qual é a probabilidade de que o ônibus tenha que esperar mais de 9 minutos? Um décimo!
Considere alguns finito intervalo, vamos para definição será um segmento. Se um valor aleatório tem permanente densidade de probabilidade em um determinado segmento e densidade zero fora dele, então dizemos que ele é distribuído uniformemente. Neste caso, a função de densidade será estritamente definida: 
Com efeito, se o comprimento do segmento (ver desenho)é , então o valor é inevitavelmente igual - para obter a unidade de área do retângulo, e foi observado propriedade conhecida:
Vamos verificar formalmente:
, h.t.p. Do ponto de vista probabilístico, isso significa que a variável aleatória de forma confiável vai pegar um dos valores do segmento..., eh, aos poucos estou virando um velho chato =)
A essência da uniformidade é que não importa qual lacuna interna comprimento fixo nós não consideramos (lembre-se dos minutos do "ônibus")- a probabilidade de uma variável aleatória assumir um valor desse intervalo será a mesma. No desenho, sombreei três dessas probabilidades - mais uma vez chamo a atenção para o fato de que eles são determinados pelas áreas, não valores de função!
Considere uma tarefa típica:
Exemplo 1
Uma variável aleatória contínua é dada por sua densidade de distribuição: ![]()
Encontre a constante , calcule e componha a função de distribuição. Construir gráficos. Achar
Em outras palavras, tudo o que você poderia sonhar :)
Solução: desde no intervalo (intervalo terminal) ![]() , então a variável aleatória tem uma distribuição uniforme, e o valor de "ce" pode ser encontrado pela fórmula direta
, então a variável aleatória tem uma distribuição uniforme, e o valor de "ce" pode ser encontrado pela fórmula direta ![]() . Mas é melhor de uma forma geral - usando uma propriedade:
. Mas é melhor de uma forma geral - usando uma propriedade:
…por que é melhor? Sem mais perguntas ;)
Então a função densidade é: 
Vamos fazer o truque. valores impossível
, e, portanto, os pontos em negrito são colocados na parte inferior: 
Para uma verificação rápida, vamos calcular a área do retângulo: ![]() , h.t.p.
, h.t.p.
Vamos encontrar valor esperado, e, provavelmente, você já adivinhou a que é igual. Lembre-se do ônibus "10 minutos": se aleatoriamente pare por muitos e muitos dias, salve-me, então média você tem que esperar 5 minutos.
Sim, isso mesmo - a expectativa deve estar exatamente no meio do intervalo "evento":
, como esperado.
Calculamos a dispersão por Fórmula ![]() . E aqui você precisa de olho e olho ao calcular a integral:
. E aqui você precisa de olho e olho ao calcular a integral:
Nesse caminho, dispersão: ![]()
vamos compor função de distribuição ![]() . Nada de novo aqui:
. Nada de novo aqui:
1) se , então e ![]() ;
;
2) se , então e:
3) e, finalmente, em ![]() , é por isso:
, é por isso:
Como resultado: 
Vamos executar o desenho: 
No intervalo "ao vivo", a função de distribuição cresce linearmente, e este é outro sinal de que temos uma variável aleatória uniformemente distribuída. Bem, ainda assim, afinal derivado Função linear- é uma constante.
A probabilidade necessária pode ser calculada de duas maneiras, usando a função de distribuição encontrada:
ou usando uma integral definida de densidade: 
Quem gosta.
E aqui você também pode escrever responda: , , os gráficos são construídos ao longo da solução.
, os gráficos são construídos ao longo da solução.
... "é possível", porque geralmente não punem por sua ausência. Usualmente;)
Existem fórmulas especiais para calcular e variável aleatória uniforme, que sugiro que você mesmo deduza:
Exemplo 2
Variável aleatória contínua definida pela densidade  .
.
Calcule a expectativa matemática e a variância. Simplifique os resultados (fórmulas de multiplicação abreviadas ajudar).
É conveniente usar as fórmulas obtidas para verificação, em particular, verifique o problema que você acabou de resolver substituindo os valores específicos de "a" e "b" neles. Breve solução na parte inferior da página.
E no final da lição, analisaremos algumas tarefas de “texto”:
Exemplo 3
O valor da divisão da escala do instrumento de medição é 0,2. As leituras do instrumento são arredondadas para a divisão inteira mais próxima. Supondo que os erros de arredondamento sejam distribuídos uniformemente, encontre a probabilidade de que durante a próxima medição não exceda 0,04.
Para melhor compreensão soluções imagine que seja algum tipo de dispositivo mecânico com uma flecha, por exemplo, balança com valor de divisão de 0,2 kg, e temos que pesar um porco em uma cutucada. Mas não para descobrir sua gordura - agora será importante ONDE a flecha irá parar entre duas divisões adjacentes.
Considere uma variável aleatória - distância flechas fora mais próximo divisão esquerda. Ou da direita mais próxima, não importa.
Vamos compor a função de densidade de probabilidade:
1) Como a distância não pode ser negativa, então no intervalo . Logicamente.
2) Segue-se da condição que a flecha da balança com igualmente provável pode parar em qualquer lugar entre as divisões *
, incluindo as próprias divisões e, portanto, no intervalo: ![]()
* Esta é uma condição essencial. Assim, por exemplo, ao pesar pedaços de algodão ou pacotes de quilos de sal, a uniformidade será observada em intervalos muito mais estreitos.
3) E como a distância da divisão esquerda MAIS PRÓXIMA não pode ser maior que 0,2, então for também é zero.
Nesse caminho: 
Deve-se notar que ninguém nos perguntou sobre a função de densidade e dei sua construção completa exclusivamente em circuitos cognitivos. Ao finalizar a tarefa, basta anotar apenas o 2º parágrafo.
Agora vamos responder à pergunta do problema. Quando o erro de arredondamento para a divisão mais próxima não excede 0,04? Isso acontecerá quando a seta parar a não mais de 0,04 da divisão esquerda na direita ou não mais do que 0,04 da divisão certa deixei. No desenho, sombreei as áreas correspondentes: 
Resta encontrar essas áreas com ajuda de integrais. Em princípio, eles também podem ser calculados “à maneira escolar” (como as áreas dos retângulos), mas a simplicidade nem sempre encontra compreensão;)
Por teorema da adição para as probabilidades de eventos incompatíveis:
- a probabilidade de o erro de arredondamento não exceder 0,04 (40 gramas para o nosso exemplo)
É fácil entender que o erro máximo de arredondamento possível é de 0,1 (100 gramas) e, portanto, a probabilidade de que o erro de arredondamento não exceda 0,1é igual a um. E disso, aliás, segue outra maneira mais fácil de resolver, na qual você precisa considerar uma variável aleatória – erro de arredondamento para a divisão mais próxima. Mas o primeiro me veio à mente primeiro :)
Responda: 0,4
E mais um ponto na tarefa. A condição pode conter erros. não arredondamento, mas o aleatória erros as próprias medidas, que geralmente são (Mas não sempre), são distribuídos de acordo com a lei normal. Nesse caminho, Apenas uma palavra pode mudar sua mente! Esteja alerta e mergulhe no significado das tarefas!
E assim que tudo gira em círculo, nossos pés nos levam à mesma parada:
Exemplo 4
Os ônibus de uma determinada rota seguem rigorosamente de acordo com o horário e com intervalo de 7 minutos. Componha uma função da densidade de uma variável aleatória - o tempo de espera do próximo ônibus por um passageiro que se aproximou aleatoriamente do ponto de ônibus. Encontre a probabilidade de que ele espere pelo ônibus não mais do que três minutos. Encontre a função de distribuição e explique seu significado significativo.
Como exemplo de uma variável aleatória contínua, considere uma variável aleatória X uniformemente distribuída no intervalo (a; b). Dizemos que a variável aleatória X distribuído uniformemente no intervalo (a; b), se sua densidade de distribuição não for constante neste intervalo:
A partir da condição de normalização, determinamos o valor da constante c . A área sob a curva de densidade de distribuição deve ser igual a um, mas no nosso caso é a área de um retângulo com base (b - α) e altura c (Fig. 1). 
Arroz. 1 Densidade de distribuição uniforme
A partir daqui encontramos o valor da constante c: ![]()
Então, a densidade de uma variável aleatória uniformemente distribuída é igual a 
Vamos agora encontrar a função de distribuição pela fórmula:
1) para ![]()
2) para
3) para 0+1+0=1.
Nesse caminho, 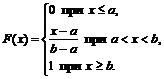
A função de distribuição é contínua e não decresce (Fig. 2). 
Arroz. 2 Função de distribuição de uma variável aleatória uniformemente distribuída
Vamos encontrar expectativa matemática de uma variável aleatória uniformemente distribuída de acordo com a fórmula:
Variância de distribuição uniformeé calculado pela fórmula e é igual a
Exemplo 1. O valor da divisão da escala do instrumento de medição é 0,2 . As leituras do instrumento são arredondadas para a divisão inteira mais próxima. Encontre a probabilidade de ocorrer um erro durante a leitura: a) menor que 0,04; b) grande 0,02
Solução. O erro de arredondamento é uma variável aleatória uniformemente distribuída no intervalo entre as divisões inteiras adjacentes. Considere o intervalo (0; 0,2) como tal divisão (Fig. a). O arredondamento pode ser feito tanto para a borda esquerda - 0, quanto para a direita - 0,2, o que significa que um erro menor ou igual a 0,04 pode ser cometido duas vezes, o que deve ser levado em consideração no cálculo da probabilidade: 

P = 0,2 + 0,2 = 0,4
Para o segundo caso, o valor do erro também pode ultrapassar 0,02 em ambos os limites da divisão, ou seja, pode ser maior que 0,02 ou menor que 0,18. 
Então a probabilidade de um erro como este:
Exemplo #2. Supunha-se que a estabilidade da situação econômica do país (ausência de guerras, desastres naturais, etc.) nos últimos 50 anos pode ser julgada pela natureza da distribuição da população por idade: em uma situação calma, deveria ser uniforme. Como resultado do estudo, os seguintes dados foram obtidos para um dos países.
Há alguma razão para acreditar que havia uma situação instável no país?Realizamos a decisão usando a calculadora Teste de hipótese. Tabela para cálculo de indicadores.
| Grupos | Intervalo médio, x i | Quantidade, fi | x eu * f eu | Frequência cumulativa, S | |x - x cf |*f | (x - x sr) 2 *f | Frequência, f i / n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
média ponderada
indicadores de variação.
Taxas de Variação Absolutas.
A amplitude de variação é a diferença entre os valores máximo e mínimo do atributo da série primária.
R = X máx - X min
R=70 - 0=70
Dispersão- caracteriza a medida de dispersão em torno de seu valor médio (medida de dispersão, ou seja, desvio da média).

Desvio padrão.
Cada valor da série difere do valor médio de 43 em não mais que 23,92
Testando hipóteses sobre o tipo de distribuição.
4. Testando a hipótese sobre distribuição uniforme a população em geral.
Para testar a hipótese sobre a distribuição uniforme de X, ou seja, de acordo com a lei: f(x) = 1/(b-a) no intervalo (a,b)
necessário:
1. Estime os parâmetros a e b - os finais do intervalo em que foram observados os possíveis valores de X, de acordo com as fórmulas (o sinal * denota as estimativas dos parâmetros):
2. Encontre a densidade de probabilidade da distribuição estimada f(x) = 1/(b * - a *)
3. Encontre frequências teóricas:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Compare as frequências empíricas e teóricas usando o teste de Pearson, assumindo o número de graus de liberdade k = s-3, onde s é o número de intervalos amostrais iniciais; se, no entanto, foi feita uma combinação de pequenas frequências e, portanto, os próprios intervalos, então s é o número de intervalos restantes após a combinação.
Solução:
1. Encontre as estimativas dos parâmetros a * e b * da distribuição uniforme usando as fórmulas:
2. Encontre a densidade da distribuição uniforme assumida:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Encontre as frequências teóricas:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Os restantes n s serão iguais:
n s = n*f(x)(x i - x i-1)
| eu | n eu | n*eu | n eu - n * eu | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Total | 1 | 0.0532 |
Portanto, a região crítica para esta estatística é sempre destra: , se a densidade de distribuição for constante neste segmento, e igual a 0 fora dele.
A curva de distribuição uniforme é mostrada na fig. 3.13.

Arroz. 3.13.
Valores/ (X) nos extremos uma e b enredo (a, b) não são indicados, pois a probabilidade de acertar algum desses pontos para uma variável aleatória contínua x igual a 0.
Expectativa matemática de uma variável aleatória x, que tem uma distribuição uniforme na seção [a, d], / « = (a + b)/2. A dispersão é calculada pela fórmula D =(b- a) 2/12, portanto st = (b- a) / 3.464.
Modelação de variáveis aleatórias. Para modelar uma variável aleatória, é necessário conhecer sua lei de distribuição. A forma mais comum de obter uma sequência de números aleatórios distribuídos segundo uma lei arbitrária é o método baseado na sua formação a partir da sequência original de números aleatórios distribuídos no intervalo (0; 1) segundo uma lei uniforme.
distribuído uniformemente no intervalo (0; 1) sequências de números aleatórios podem ser obtidas de três maneiras:
- de acordo com tabelas especialmente preparadas de números aleatórios;
- usando geradores físicos de números aleatórios (por exemplo, jogando uma moeda);
- método algorítmico.
Para tais números, o valor da expectativa matemática deve ser igual a 0,5 e a variância deve ser 1/12. Se necessário, o número aleatório x estava no intervalo ( uma; b) diferente de (0; 1), você precisa usar a fórmula X \u003d a + (b - a) g, Onde G- um número aleatório do intervalo (0; 1).
Devido ao fato de quase todos os modelos serem implementados em um computador, quase sempre um gerador algorítmico (RNG) embutido no computador é usado para obter números aleatórios, embora não seja um problema usar tabelas que foram previamente convertidas em formato eletrônico . Deve-se ter em mente que, pelo método algorítmico, sempre obtemos números pseudo-aleatórios, pois cada número gerado subsequentemente depende do anterior.
Na prática, é sempre necessário obter números aleatórios distribuídos de acordo com uma dada lei de distribuição. Para isso, uma variedade de métodos são usados. Se a expressão analítica para a lei de distribuição for conhecida F, então você pode usar método da função inversa.
Basta jogar um número aleatório uniformemente distribuído no intervalo de 0 a 1. Como a função F também varia neste intervalo, então o número aleatório x pode ser determinado tomando a função inversa de um gráfico ou analiticamente: x=F"(d). Aqui G- o número gerado pelo RNG no intervalo de 0 a 1; x té a variável aleatória resultante. Graficamente, a essência do método é mostrada na Fig. 3.14.

Arroz. 3.14. Ilustração do método de função inversa para gerar eventos aleatórios x, cujos valores são distribuídos continuamente. A figura mostra gráficos da densidade de probabilidade e da densidade de probabilidade integral de x
Considere, como exemplo, a lei da distribuição exponencial. A função de distribuição desta lei tem a forma F(x) = 1 -exp(-bz). Porque G e F neste método são considerados semelhantes e localizados no mesmo intervalo, então, substituindo F para um número aleatório r, temos G= 1 - exp(-bz). Expressando o valor desejado x desta expressão (isto é, invertendo a função exp()), obtemos x = -/X? 1p(1 -G). Visto que no sentido estatístico (1 - d) e G-é a mesma coisa então x \u003d -YX 1p(r).
Algoritmos para modelar algumas leis comuns de distribuição de variáveis aleatórias contínuas são fornecidos na Tabela. 3.10.
Por exemplo, é necessário simular o tempo de carregamento, que é distribuído de acordo com a lei normal. Sabe-se que a duração média do carregamento é de 35 minutos e o desvio padrão do tempo real do valor médio é de 10 minutos. Ou seja, de acordo com as condições da tarefa t x = 35, com x= 10. Então o valor da variável aleatória será calculado pela fórmula R= ?g, onde G. - números aleatórios do RNG no intervalo, n = 12. O número 12 é escolhido como grande o suficiente com base no teorema do limite central da teoria da probabilidade (teorema de Lyapunov): “Para um grande número N variáveis aleatórias x com qualquer lei de distribuição, sua soma é um número aleatório com uma lei de distribuição normal. Então o valor aleatório x\u003d o (7? - l / 2) + t x = 10(7? -3) + 35.
Tabela 3.10
Algoritmos para modelar variáveis aleatórias
Simulação de um evento aleatório. Um evento aleatório implica que algum evento tem vários resultados e qual dos resultados acontecerá novamente é determinado apenas por sua probabilidade. Ou seja, o resultado é escolhido aleatoriamente, levando em consideração sua probabilidade. Por exemplo, suponha que conheçamos a probabilidade de produzir produtos defeituosos R= 0,1. Você pode simular a ocorrência desse evento reproduzindo um número aleatório distribuído uniformemente no intervalo de 0 a 1 e estabelecendo em qual dos dois intervalos (de 0 a 0,1 ou de 0,1 a 1) caiu (Fig. 3.15). Se o número estiver dentro do intervalo (0; 0,1), foi emitido um defeito, ou seja, o evento ocorreu, caso contrário, o evento não ocorreu (foi produzido um produto condicionado). Com um número significativo de experimentos, a frequência de números caindo no intervalo de 0 a 0,1 se aproximará da probabilidade P= 0,1, e a frequência de acertar números no intervalo de 0,1 a 1 se aproximará de P. = 0,9.

Arroz. 3.15.
Os eventos são chamados incompatível, se a probabilidade de ocorrência desses eventos simultaneamente for igual a 0. Segue-se que a probabilidade total de um grupo de eventos incompatíveis é igual a 1. Denote por um r EU, um eventos e através Р ]9 Р 2 , ..., R p- a probabilidade de ocorrência de eventos individuais. Como os eventos são incompatíveis, a soma das probabilidades de sua ocorrência é igual a 1: P x + P 2 + ... +Pn= 1. Novamente, usamos um gerador de números aleatórios para simular a ocorrência de um dos eventos, cujo valor também está sempre no intervalo de 0 a 1. Vamos separar segmentos no intervalo unitário P r P v ..., R pág.É claro que a soma dos segmentos será exatamente um intervalo unitário. O ponto correspondente ao número descartado do gerador de números aleatórios neste intervalo apontará para um dos segmentos. Conseqüentemente, os números aleatórios cairão em grandes segmentos com mais frequência (a probabilidade de ocorrência desses eventos é maior!), Em segmentos menores - com menos frequência (Fig. 3.16).
Se necessário, simulação eventos conjuntos eles devem ser incompatíveis. Por exemplo, para simular a ocorrência de eventos para os quais as probabilidades são dadas R(a() = 0,7; P(a 2)= 0,5 e P(a]9 a 2)= 0,4, definimos todos os possíveis resultados incompatíveis da ocorrência de eventos a d a 2 e sua aparição simultânea:
- 1. Ocorrência simultânea de dois eventos P(b () = P(a L , a 2) = 0,4.
- 2. Ocorrência do evento a ] P (b 2) \u003d P (a y) - P (a ( , a 2) = 0,7 - 0,4 = 0,3.
- 3. Ocorrência do evento a 2P(b 3) = P (a 2) - P (a g a 2) \u003d 0,5 - 0,4 = 0,1.
- 4. Não aparecimento de qualquer evento P(b 4) = 1 - (P(b) + P(b 2) + + P(b 3)) =0,2.
Já as probabilidades de ocorrência de eventos incompatíveis b devem ser representados no eixo numérico como segmentos. Recebendo números com a ajuda do RNG, determinamos sua pertença a um determinado intervalo e obtemos a implementação de eventos conjuntos uma.

Arroz. 3.16.
Frequentemente encontrado na prática sistemas de variáveis aleatórias, ou seja, essas duas (ou mais) variáveis aleatórias diferentes x, No(e outros) que dependem uns dos outros. Por exemplo, se ocorrer um evento x e tomou algum valor aleatório, então o evento No acontece, ainda que por acaso, mas levando em consideração o fato de que x já assumiu algum valor.
Por exemplo, se como x um grande número caiu, então como No um número suficientemente grande também deve cair (se a correlação for positiva e vice-versa se for negativa). No transporte, essas dependências são bastante comuns. Atrasos maiores são mais prováveis em rotas mais longas, etc.
Se variáveis aleatórias são dependentes, então
f(x)=f(x l)f(x 2 x l)f(x 3 x 2 ,x l)- ... -/(xjx, r X„ , ...,x 2 ,x t), Onde x. | x._ v x (- variáveis dependentes aleatórias: abandono X. desde que caiam x._ (9 x._ ( ,...,*,) - densidade condicional
probabilidade de ocorrência x.> se desistiu x._ (9 ..., x ( ;f(x) - a probabilidade de cair fora do vetor x de variáveis dependentes aleatórias.
Coeficiente de correlação q mostra como os eventos estão intimamente relacionados Hee W. Se o coeficiente de correlação for igual a um, então a dependência dos eventos hee woo um-para-um: um valor x corresponde a um valor No(Fig. 3.17, uma) . No q próximo da unidade, a figura mostrada na Fig. 3.17, b, ou seja, um valor x já pode corresponder a vários valores de Y (mais precisamente, um dos vários valores de Y, determinados aleatoriamente); ou seja, neste evento x e Y menos correlacionados, menos dependentes uns dos outros.

Arroz. 3.17. Tipo de dependência de duas variáveis aleatórias com um coeficiente de correlação positivo: uma- no q = 1; b- a 0 q em q, perto de O
E, finalmente, quando o coeficiente de correlação tende a zero, surge uma situação em que qualquer valor x pode corresponder a qualquer valor de Y, ou seja, eventos x e Y não dependem ou quase não dependem um do outro, não se correlacionam (Fig. 3.17, dentro).
Por exemplo, vamos pegar a distribuição normal, como a mais comum. A expectativa matemática indica os eventos mais prováveis, aqui o número de eventos é maior e o cronograma de eventos é mais denso. Uma correlação positiva indica que grandes variáveis aleatórias x causa para gerar grandes Y. Correlação zero e próxima de zero mostra que o valor da variável aleatória x não tem nada a ver com um certo valor de uma variável aleatória Y.É fácil entender o que foi dito se primeiro imaginarmos as distribuições f(X) e / (Y) separadamente e, em seguida, conecte-os em um sistema, conforme mostrado na Fig. 3.18.
Neste exemplo Hee Y são distribuídos de acordo com a lei normal com os valores correspondentes tx, um e este, uma,. O coeficiente de correlação de dois eventos aleatórios é dado q, ou seja, variáveis aleatórias x e Y são dependentes um do outro, Y não é totalmente acidental.
Então um possível algoritmo para implementação do modelo será o seguinte:
1. Seis números aleatórios distribuídos uniformemente no intervalo são jogados: b p b:, bi, b 4 , b 5, b 6 ; encontre sua soma S:
S = b. O número aleatório normalmente distribuído l é encontrado: de acordo com a seguinte fórmula: x \u003d a (5 - 6) + tx.
- 2. De acordo com a fórmula m! x = este + qoJo x (x -m x)é a esperança matemática t y1x(sinal u/x significa que y assumirá valores aleatórios, dada a condição de que * já assumiu alguns determinados valores).
- 3. De acordo com a fórmula = a d/l -C 2 encontre o desvio padrão a..
4. São jogados 12 números aleatórios r distribuídos uniformemente no intervalo; encontre sua soma k:k= Zr. Encontre um número aleatório normalmente distribuído no de acordo com a seguinte fórmula: y = °Jk-6) + mr/x.

Arroz. 3.18.
Modelando o fluxo de um evento. Quando há muitos eventos e eles se sucedem, eles formam fluxo. Observe que os eventos neste caso devem ser homogêneos, ou seja, semelhantes de alguma forma entre si. Por exemplo, o aparecimento de motoristas em postos de gasolina que desejam reabastecer o carro. Ou seja, eventos homogêneos formam uma série. Supõe-se que a característica estatística deste 146
fenômenos (intensidade do fluxo de eventos) é dado. A intensidade do fluxo de eventos indica quantos desses eventos ocorrem em média por unidade de tempo. Mas quando exatamente cada evento específico ocorrerá, é necessário determinar por métodos de modelagem. É importante que quando geramos, por exemplo, 1000 eventos em 200 horas, seu número seja aproximadamente igual à intensidade média de ocorrência dos eventos 1000/200 = 5 eventos por hora. Este é um valor estatístico que caracteriza este fluxo como um todo.
A intensidade do fluxo em certo sentido é a expectativa matemática do número de eventos por unidade de tempo. Mas, na realidade, pode acontecer que 4 eventos apareçam em uma hora e 6 em outra, embora em média sejam obtidos 5 eventos por hora, portanto, um valor não é suficiente para caracterizar o fluxo. O segundo valor que caracteriza quão grande é a dispersão dos eventos em relação à expectativa matemática é, como antes, a dispersão. É esse valor que determina a aleatoriedade da ocorrência de um evento, a fraca previsibilidade do momento de sua ocorrência.
Fluxos aleatórios são:
- ordinário - a probabilidade da ocorrência simultânea de dois ou mais eventos é zero;
- estacionário - frequência de ocorrência de eventos x constante;
- sem efeito posterior - a probabilidade de ocorrência de um evento aleatório não depende do momento dos eventos anteriores.
Ao modelar QS, na grande maioria dos casos, considera-se Fluxo de Poisson (mais simples) - fluxo normal sem efeito posterior, em que a probabilidade de chegada no intervalo de tempo t suave t requisitos é dada pela fórmula de Poisson:
Um fluxo de Poisson pode ser estacionário se A.(/) = const(/), ou não estacionário caso contrário.
Em um fluxo de Poisson, a probabilidade de nenhum evento ocorrer é
Na fig. 3.19 mostra a dependência R de tempos. Obviamente, quanto maior o tempo de observação, menor a probabilidade de nenhum evento ocorrer. Além disso, quanto maior o valor x, quanto mais íngreme for o gráfico, ou seja, mais rápido a probabilidade diminui. Isso corresponde ao fato de que se a intensidade da ocorrência de eventos for alta, então a probabilidade de que o evento não ocorra diminui rapidamente com o tempo de observação.

Arroz. 3.19.
Probabilidade de pelo menos um evento ocorrer P = 1 - shr(-Inferno), desde P + P = .É óbvio que a probabilidade de ocorrência de pelo menos um evento tende à unidade com o tempo, ou seja, com uma observação de longo prazo apropriada, o evento necessariamente ocorrerá mais cedo ou mais tarde. Dentro do significado da Ré igual a r, portanto, expressando / da fórmula de definição R, finalmente, para determinar os intervalos entre dois eventos aleatórios, temos
![]()
Onde G- um número aleatório distribuído uniformemente de 0 a 1, que é obtido usando o RNG; t- intervalo entre eventos aleatórios (variável aleatória).
Como exemplo, considere o fluxo de carros que chegam ao terminal. Os carros chegam aleatoriamente - uma média de 8 por dia (taxa de fluxo x= 8/24 veículos/h). preciso ver 148
compartilhar este processo em T\u003d 100 horas Intervalo de tempo médio entre carros / \u003d 1 / L. = 24/8 = 3 horas
Na fig. 3.20 mostra o resultado da simulação - os momentos no tempo em que os carros chegaram ao terminal. Como se vê, apenas no período T = 100 terminais processados N=33 carro. Se executarmos a simulação novamente, então N pode ser igual a, por exemplo, 34, 35 ou 32. Mas em média para Para algoritmo é executado N será igual a 33,333.
Arroz. 3.20.
Se for conhecido que o fluxo não é comum então é necessário modelar, além do momento de ocorrência do evento, também a quantidade de eventos que poderiam ocorrer naquele momento. Por exemplo, os carros chegam ao terminal em horários aleatórios (fluxo normal de carros). Mas, ao mesmo tempo, os carros podem ter uma quantidade diferente (aleatória) de carga. Neste caso, diz-se que o fluxo de carga é fluxo de eventos extraordinários.
Vamos considerar o problema. É necessário determinar o tempo ocioso do equipamento de carregamento no terminal se os contêineres AUK-1.25 forem entregues ao terminal por caminhões. O fluxo de carros obedece a lei de Poisson, o intervalo médio entre os carros é 0,5 hD = 1/0,5 = 2 carros/hora. O número de contêineres em um carro varia de acordo com a lei normal com um valor médio t= 6 e a = 2. Nesse caso, o mínimo pode ser 2 e o máximo - 10 contêineres. O tempo de descarga de um contêiner é de 4 minutos e 6 minutos são necessários para operações tecnológicas. O algoritmo para resolver esse problema, construído com base no princípio de postagem sequencial de cada aplicativo, é mostrado na Fig. 3.21.
Depois de inserir os dados iniciais, o ciclo de simulação é iniciado até que o tempo de simulação especificado seja atingido. Usando o RNG, obtemos um número aleatório e determinamos o intervalo de tempo antes da chegada do carro. Marcamos o intervalo resultante no eixo do tempo e simulamos o número de contêineres na carroceria do carro que chegou.
Verificamos o número resultante para um intervalo aceitável. Em seguida, o tempo de descarga é calculado e somado no contador do tempo total de operação do equipamento de carregamento. Verifica-se a condição: se o intervalo de chegada do vagão for maior que o tempo de descarga, então a diferença entre eles é somada no contador de paradas do equipamento.

Arroz. 3.21.
Um exemplo típico de um CMO seria um ponto de carregamento com vários postes, conforme mostrado na Fig. 3.22.

Arroz. 3.22.
Para maior clareza do processo de modelagem, vamos construir um diagrama de tempo da operação QS, refletindo em cada régua (eixo do tempo /) o estado de um elemento separado do sistema (Fig. 3.23). Existem tantas linhas de tempo quanto objetos diferentes no QS (fluxos). No nosso exemplo, são 7 deles: o fluxo de pedidos, o fluxo de espera em primeiro lugar da fila, o fluxo de espera em segundo lugar na fila, o fluxo de atendimento no primeiro canal, o fluxo de atendimento no segundo canal, o fluxo de requisições atendidas pelo sistema, o fluxo de requisições recusadas. Para demonstrar o processo de negação de serviço, vamos supor que apenas dois carros possam estar na fila para carregamento. Se houver mais deles, eles serão enviados para outro ponto de carregamento.
Os momentos aleatórios simulados de recebimento de pedidos de manutenção do carro são exibidos na primeira linha. A primeira requisição é atendida e, como os canais estão livres neste momento, é colocado para atendimento no primeiro canal. Solicitar 1 transferido para a linha do primeiro canal. O tempo de atendimento no canal também é aleatório. Encontramos no diagrama o momento do término do atendimento, postergando o tempo de atendimento gerado a partir do momento em que o atendimento foi iniciado.
niya e omita o aplicativo para a linha "Servido". O aplicativo passou pelo CMO todo o caminho. Agora, de acordo com o princípio de postagem sequencial de pedidos, também é possível simular o caminho do segundo pedido.

Arroz. 3.23.
Se em algum momento ambos os canais estiverem ocupados, a solicitação deve ser colocada na fila. Na fig. 3.23 é um aplicativo 3. Observe que, de acordo com as condições da tarefa, na fila, ao contrário dos canais, os aplicativos não são localizados aleatoriamente, mas aguardam até que um dos canais fique livre. Após a liberação do canal, a solicitação é movida para a linha do canal correspondente e seu atendimento é organizado ali.
Se o peso do lugar na fila no momento da chegada do próximo pedido estiver ocupado, o pedido deve ser enviado para a linha "Recusado". Na fig. 3.23 é um aplicativo 6.
O procedimento de imitação de serviço de aplicativos é continuado por algum tempo T. Quanto maior esse tempo, mais precisos serão os resultados da simulação no futuro. Na realidade, para sistemas simples, escolha T, igual a 50-100 horas ou mais, embora às vezes seja melhor medir esse valor pelo número de aplicações consideradas.
Analisaremos o QS usando o exemplo já considerado.
Primeiro você precisa esperar pelo estado estacionário. Descartamos as quatro primeiras aplicações como atípicas, ocorrendo durante o processo de estabelecimento do funcionamento do sistema (“tempo de aquecimento do modelo”). Medimos o tempo de observação, digamos que em nosso exemplo T = 5 horas. Calculamos o número de solicitações atendidas do diagrama N o6c , tempo ocioso e outros valores. Como resultado, podemos calcular indicadores que caracterizam a qualidade do trabalho QS:
- 1. Probabilidade de Serviço P \u003d N, / N \u003d 5/7 = 0,714. Para calcular a probabilidade de atendimento de um aplicativo no sistema, basta dividir o número de aplicativos que foram atendidos durante o tempo T(consulte a linha “Atendidos”), L/o6s por número de solicitações N, que chegaram ao mesmo tempo.
- 2. Rendimento do sistema A \u003d NJT h \u003d 7/5 \u003d 1,4 auto / h. Para calcular o throughput do sistema, basta dividir o número de requisições atendidas N o6c por um tempo T, para o qual este serviço foi realizado.
- 3. Probabilidade de falha P \u003d N / N \u003d 3/7 \u003d 0,43. Para calcular a probabilidade de negação de serviço a um pedido, basta dividir o número de pedidos N que foram negados por tempo T(ver a linha "Rejeitado"), para o número de pedidos N, que queria servir durante o mesmo tempo, ou seja, entrou no sistema. Observe que a quantidade R op + R p (k em teoria deveria ser igual a 1. Na verdade, descobriu-se experimentalmente que R + R.= 0,714 + 0,43 = 1,144. Esta imprecisão é explicada pelo fato de que durante a observação T estatísticas insuficientes foram acumuladas para obter uma resposta precisa. O erro deste indicador é agora de 14%.
- 4. Probabilidade de um canal estar ocupado P = T r JT H= 0,05/5 = 0,01, onde T- tempo ocupado de apenas um canal (primeiro ou segundo). As medições estão sujeitas a intervalos de tempo em que certos eventos ocorrem. Por exemplo, no diagrama, esses segmentos são procurados quando o primeiro ou o segundo canal está ocupado. Neste exemplo, existe um segmento no final do diagrama com duração de 0,05 horas.
- 5. Probabilidade de dois canais estarem ocupados P = T / T = 4,95/5 = 0,99. No diagrama, esses segmentos são procurados, durante os quais o primeiro e o segundo canais são ocupados simultaneamente. Neste exemplo, existem quatro desses segmentos, sua soma é de 4,95 horas.
- 6. Número médio de canais ocupados: /V a - 0 P 0 + P X + 2 P, \u003d \u003d 0,01 +2? 0,99 = 1,99. Para calcular quantos canais estão ocupados no sistema em média, basta conhecer o share (probabilidade de ocupação de um canal) e multiplicar pelo peso desse share (um canal), conhecer o share (probabilidade de ocupação de dois canais) e multiplicar pelo peso deste compartilhamento (dois canais) e etc. O valor resultante de 1,99 indica que dos dois canais possíveis, 1,99 canais são carregados em média. Esta é uma alta taxa de utilização de 99,5%, o sistema está fazendo bom uso dos recursos.
- 7. Probabilidade de tempo ocioso de pelo menos um canal Р*, = Г é simples, /Г = = 0,05/5 = 0,01.
- 8. Probabilidade de indisponibilidade de dois canais ao mesmo tempo: P = = TJT = 0.
- 9. Probabilidade de inatividade de todo o sistema P* \u003d T / T \u003d 0.
- 10. O número médio de aplicativos na fila / V s = 0 P(h + 1 Р e + 2Р b= = 0,34 + 2 0,64 = 1,62 aut. Para determinar o número médio de aplicativos na fila, é necessário determinar separadamente a probabilidade de haver um aplicativo P na fila, a probabilidade de haver dois aplicativos P 2s na fila e assim por diante, e adicionar novamente com os pesos apropriados.
- 11. A probabilidade de haver um aplicativo na fila, P e = = TJTn= 1,7 / 5 \u003d 0,34 (existem quatro desses segmentos no diagrama, totalizando 1,7 horas).
- 12. A probabilidade de dois aplicativos estarem na fila ao mesmo tempo, R b\u003d Г 2з / Г \u003d 3,2 / 5 \u003d 0,64 (existem três desses segmentos no diagrama, totalizando 3,25 horas).
- 13. O tempo médio de espera de um pedido na fila é Tro = 1,7/4 = = 0,425 horas, é preciso somar todos os intervalos de tempo em que algum pedido ficou na fila e dividir pelo número de pedidos. Existem 4 solicitações desse tipo na linha do tempo.
- 14. Tempo médio de atendimento para um aplicativo 7' srobsl = 8/5 = 1,6 horas Some todos os intervalos de tempo durante os quais qualquer aplicativo foi atendido em qualquer canal e divida pelo número de aplicativos.
- 15. Tempo médio gasto por um aplicativo no sistema: T = T +
você se casou cantado casar. oh
Se a precisão não for satisfatória, você deve aumentar o tempo do experimento e, assim, melhorar as estatísticas. Você pode fazer diferente se executar o experimento 154 várias vezes
por um tempo T e, posteriormente, faça a média dos valores desses experimentos e, em seguida, verifique novamente os resultados para o critério de precisão. Este procedimento deve ser repetido até que a precisão desejada seja alcançada.
Análise dos resultados da simulação
Tabela 3.11
|
Índice |
Significado indicador |
Interesses do proprietário da CMO |
Interesses do cliente |
|
Probabilidade serviço |
A probabilidade de atendimento é baixa, muitos clientes saem do sistema sem atendimento Recomendação: aumentar a probabilidade de atendimento |
Possibilidade de atendimento é baixa, cada terceiro cliente quer ser atendido mas não consegue Recomendação: aumentar a probabilidade de atendimento |
|
|
Número médio de aplicativos na fila |
O carro quase sempre fica na fila antes de ser atendido Recomendação: aumentar o número de lugares na fila, aumentar a capacidade |
||
|
Aumente o throughput Aumente o número de lugares na fila para não perder clientes em potencial |
Os clientes estão interessados em um aumento significativo na taxa de transferência para reduzir a latência e reduzir as falhas |
Para tomar uma decisão sobre a implementação de atividades específicas, é necessário realizar uma análise de sensibilidade do modelo. Alvo análise de sensibilidade do modeloé determinar os possíveis desvios das características de saída devido a mudanças nos parâmetros de entrada.
Os métodos para avaliar a sensibilidade de um modelo de simulação são semelhantes aos métodos para determinar a sensibilidade de qualquer sistema. Se a característica de saída do modelo R depende dos parâmetros associados às variáveis R =/(p g p 2 , p), então essas mudanças
parâmetros D r.(/ = 1, ..G) causar uma mudança AR.

Neste caso, a análise de sensibilidade do modelo se reduz ao estudo da função de sensibilidade DR/outros
Como exemplo de análise de sensibilidade de um modelo de simulação, vamos considerar o efeito da alteração dos parâmetros variáveis de confiabilidade do veículo na eficiência operacional. Como função objetivo, utilizamos o indicador de custos reduzidos Ç ir. Para análise de sensibilidade, usamos dados sobre a operação do trem rodoviário KamAZ-5410 em condições urbanas. Limites de alteração de parâmetro R. para determinar a sensibilidade do modelo, basta determiná-lo por meios especializados (Tabela 3.12).
Para realizar os cálculos de acordo com o modelo, foi escolhido um ponto base, no qual os parâmetros das variáveis possuem valores que correspondem aos padrões. O parâmetro de tempo de inatividade durante manutenção e reparo em dias foi substituído por um indicador específico - tempo de inatividade em dias por mil quilômetros n.
Os resultados do cálculo são mostrados nas Figs. 3.24. O ponto base está na interseção de todas as curvas. Mostrado na fig. 3.24 dependências permitem estabelecer o grau de influência de cada um dos parâmetros em consideração na magnitude da mudança Z pr. Ao mesmo tempo, o uso de valores naturaisdas grandezas analisadas não permite estabelecer o grau comparativo de influência de cada parâmetro em 3, uma vez que esses parâmetros possuem diferentes unidades de medida. Para contornar isso, optamos pela forma de interpretação dos resultados dos cálculos em unidades relativas. Para fazer isso, o ponto base deve ser movido para a origem das coordenadas, e os valores dos parâmetros variáveis e a mudança relativa nas características de saída do modelo devem ser expressos em porcentagem. Os resultados das transformações realizadas são apresentados na fig. 3.25.
Tabela 3.12
valores parâmetros variáveis

Arroz. 3.24.

Arroz. 3.25. Influência da mudança relativa de parâmetros variáveis no grau de mudança
A mudança nos parâmetros variáveis em relação ao valor base é representada em um eixo. Como pode ser visto a partir da fig. 3.25, um aumento no valor de cada parâmetro próximo ao ponto base em 50% leva a um aumento em Z pr em 9% do crescimento de Ts a, em mais de 1,5% de C p, em menos de 0,5% de H e diminuir 3 em quase 4% do aumento eu. Diminuir em 25 % b cr e D rg leva a um aumento em Z pr, respectivamente, em mais de 6%. Diminuindo pela mesma quantidade de parâmetros H t0 , C tr e C a levam a uma diminuição de C pr em 0,2, 0,8 e 4,5%, respectivamente.
As dependências fornecidas dão uma ideia da influência de um único parâmetro e podem ser usadas ao planejar a operação do sistema de transporte. De acordo com a intensidade de influência em Z pr, os parâmetros considerados podem ser dispostos na seguinte ordem: D, II, L, C 9 N .
'a 7 k.r 7 t.r 7 t.o
Durante a operação, uma alteração no valor de um indicador implica uma alteração nos valores de outros indicadores, e a alteração relativa em cada um dos parâmetros variáveis pelo mesmo valor no caso geral tem uma base física desigual. É necessário substituir a variação relativa dos valores dos parâmetros variáveis em percentual ao longo da abcissa por um parâmetro que possa servir como medida única para avaliar o grau de variação de cada parâmetro. Pode-se supor que em cada momento da operação do veículo, o valor de cada parâmetro tem o mesmo peso econômico em relação aos valores de outros parâmetros variáveis, ou seja, do ponto de vista econômico, a confiabilidade do veículo em cada momento do tempo tem um efeito de equilíbrio em todos os parâmetros associados a ele. Então o equivalente econômico requerido será o tempo ou, mais convenientemente, o ano de operação.
Na fig. 3.26 mostra as dependências construídas de acordo com os requisitos acima. O valor no primeiro ano de operação do veículo é tomado como valor base de Z pr. Os valores dos parâmetros variáveis para cada ano de operação foram determinados com base nos resultados das observações.

Arroz. 3.26.
No processo de operação, um aumento em W pr durante os três primeiros anos deve-se principalmente a um aumento nos valores H jo , e então, nas condições operacionais consideradas, o principal papel na redução da eficiência do uso do TS é desempenhado por um aumento no C tr Para identificar a influência do valor LKp , nos cálculos, seu valor foi equiparado à quilometragem total do veículo desde o início da operação. Função tipo 3 =f(L) mostra que a intensidade da diminuição em 3 com o aumento
etc J v k.r" 7 np J
1 a p diminui significativamente.
Como resultado da análise de sensibilidade do modelo, é possível entender quais fatores precisam ser influenciados para alterar a função objetivo. Para alterar os fatores, é necessário aplicar esforços de controle, o que está associado aos custos correspondentes. A quantidade de custos não pode ser infinita, como quaisquer recursos, esses custos são na realidade limitados. Portanto, é necessário entender até que ponto a alocação de recursos será efetiva. Se na maioria dos casos os custos crescem linearmente com o aumento da ação de controle, então a eficiência do sistema cresce rapidamente apenas até um certo limite, quando mesmo custos significativos não dão mais o mesmo retorno. Por exemplo, é impossível aumentar ilimitadamente a capacidade dos dispositivos de serviço devido a limitações de espaço ou número potencial de carros atendidos, etc.
Se compararmos o aumento de custos e o indicador de eficiência do sistema nas mesmas unidades, então, via de regra, parecerá graficamente conforme mostrado na Fig. 3.27.

Arroz. 3.27.
Da fig. 3.27 verifica-se que ao atribuir um preço C, por unidade de custo Z e um preço C, por unidade de indicador R essas curvas podem ser adicionadas. As curvas se somam se precisarem ser minimizadas ou maximizadas simultaneamente. Se uma curva deve ser maximizada e a outra minimizada, então sua diferença deve ser encontrada, por exemplo, por pontos. Então a curva resultante (Fig. 3.28), que leva em conta tanto o efeito do manejo quanto os custos deste, terá um extremo. O valor do parâmetro /?, que fornece o extremo da função, é a solução do problema de síntese.

Arroz. 3.28.
para por.
Além da Gestão R e indicador R sistemas são perturbados. Perturbação D= (d v d r...) é uma ação de entrada, que, ao contrário do parâmetro de controle, não depende da vontade do proprietário do sistema (Fig. 3.29). Por exemplo, baixas temperaturas externas, concorrência, infelizmente, reduzem o fluxo de clientes; falhas de hardware reduzem o desempenho do sistema. O proprietário do sistema não pode gerenciar esses valores diretamente. Normalmente, a indignação age "apesar" do dono, reduzindo o efeito R dos esforços de gerenciamento R. Isso porque, no caso geral, o sistema é criado para atingir objetivos que são inatingíveis por si mesmos na natureza. Uma pessoa, organizando um sistema, sempre espera atingir algum objetivo por meio dele. R. Isso é o que ele coloca em seus esforços. R. Nesse contexto, podemos dizer que um sistema é uma organização de componentes naturais à disposição de uma pessoa, estudados por ela, a fim de atingir algum novo objetivo, antes inatingível de outras formas.

Arroz. 3.29.
Se removermos a dependência do indicador R da administração R mais uma vez, mas sob as condições da perturbação D, então, talvez, a natureza da curva mude. Muito provavelmente, o indicador será menor para os mesmos valores de controle, pois a perturbação é negativa, reduzindo o desempenho do sistema. Um sistema entregue a si mesmo, sem os esforços de natureza gerencial, deixa de atender ao objetivo para o qual foi criado. Se, como antes, construirmos a dependência dos custos, correlacioná-la com a dependência do indicador no parâmetro de controle, então o ponto extremo encontrado mudará (Fig. 3.30) em comparação com o caso de “perturbação = 0” (ver Fig. . 3.28). Se a perturbação aumentar novamente, as curvas mudarão e, como resultado, a posição do ponto extremo mudará novamente.
O gráfico da fig. 3.30 relaciona o indicador P, gestão (recurso) R e indignação D em sistemas complexos, indicando a melhor forma de atuação ao gestor (organização) que toma a decisão no sistema. Se a ação de controle for menor que a ótima, o efeito total diminuirá e surgirá uma situação de perda de lucro. Se a ação de controle for maior que a ideal, o efeito também diminuirá, pois pagar pela fila
Qualquer aumento no esforço de controle precisará ser maior do que o resultado do uso do sistema.

Arroz. 3.30.
Um modelo de simulação do sistema para uso real deve ser implementado em um computador. Isso pode ser criado usando as seguintes ferramentas:
- programa de usuário universal tipo de processador matemático (MATLAB) ou planilha (Excel) ou DBMS (Access, FoxPro), que permite criar apenas um modelo relativamente simples e requer pelo menos habilidades iniciais de programação;
- linguagem de programação universal(C++, Java, Basic, etc.), que permite criar um modelo de qualquer complexidade; mas este é um processo muito demorado que requer escrever uma grande quantidade de código de programa e depuração demorada;
- linguagem de simulação especializada, que possui modelos prontos e ferramentas de programação visual projetadas para criar rapidamente a base de um modelo. Uma das mais famosas é a UML (Unified Modeling Language);
- programas de simulação, que são os meios mais populares de criar modelos de simulação. Eles permitem que você crie um modelo visualmente, apenas nos casos mais difíceis, recorrendo à escrita manual do código do programa para procedimentos e funções.
Os programas de simulação são divididos em dois tipos:
- Pacotes Versáteis de Simulação são projetados para criar vários modelos e contêm um conjunto de funções que podem ser usadas para simular processos típicos em sistemas de várias finalidades. Pacotes populares desse tipo são Arena (desenvolvedor da Rockwell Automation 1 ", EUA), Extendsim (desenvolvedor da Imagine That Ink., EUA), AnyLogic (desenvolvedor da XJ Technologies, Rússia) e muitos outros. Quase todos os pacotes universais têm versões especializadas para modelar objetos de classes específicas.
- Pacotes de simulação específicos de domínio servem para modelar tipos específicos de objetos e possuem ferramentas especializadas para isso na forma de modelos, assistentes para projetar visualmente um modelo a partir de módulos prontos, etc.
- É claro que dois números aleatórios não podem depender exclusivamente um do outro, Fig. 3.17, a é dado para clareza do conceito de correlação. 144
- Análise técnica e econômica no estudo da confiabilidade do KamAZ-5410 / Yu. G. Kotikov, I. M. Blyankinshtein, A. E. Gorev, A. N. Borisenko; LISI. L.:, 1983. 12 p.-Dep. em TsBNTI Minavtotrans RSFSR, No. 135at-D83.
- http://www.rockwellautomation.com.
- http://www.cxtcndsiin.com.
- http://www.xjtek.com.
Como mencionado anteriormente, exemplos de distribuições de probabilidade variável aleatória contínua X são:
- distribuição de probabilidade uniforme de uma variável aleatória contínua;
- distribuição de probabilidade exponencial de uma variável aleatória contínua;
- distribuição normal probabilidades de uma variável aleatória contínua.
Vamos dar o conceito de leis de distribuição uniforme e exponencial, fórmulas de probabilidade e características numéricas das funções consideradas.
| Índice | Lei de distribuição aleatória | A lei exponencial da distribuição |
|---|---|---|
| Definição | Uniforme é chamado a distribuição de probabilidade de uma variável aleatória contínua X, cuja densidade permanece constante no intervalo e tem a forma | Um exponencial (exponencial) é chamado a distribuição de probabilidade de uma variável aleatória contínua X, que é descrita por uma densidade com a forma |
 onde λ é um valor positivo constante |
||
| função de distribuição |  |
|
| Probabilidade acertando o intervalo |  |
|
| Valor esperado | ||
| Dispersão |  |
|
| Desvio padrão |  |
Exemplos de resolução de problemas sobre o tema "Leis de distribuição uniformes e exponenciais"
Tarefa 1.
Os ônibus circulam estritamente de acordo com a programação. Intervalo de movimento 7 min. Encontre: (a) a probabilidade de que um passageiro chegando a uma parada espere pelo próximo ônibus por menos de dois minutos; b) a probabilidade de um passageiro que se aproxima do ponto esperar pelo próximo ônibus por pelo menos três minutos; c) a expectativa matemática e o desvio padrão da variável aleatória X - o tempo de espera do passageiro.
Solução. 1. Pela condição do problema, uma variável aleatória contínua X=(tempo de espera do passageiro) distribuído uniformemente entre as chegadas de dois ônibus. O comprimento do intervalo de distribuição da variável aleatória X é igual a b-a=7, onde a=0, b=7.
2. O tempo de espera será inferior a dois minutos se o valor aleatório X estiver dentro do intervalo (5;7). A probabilidade de cair em um determinado intervalo é encontrada pela fórmula: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(5< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. O tempo de espera será de pelo menos três minutos (ou seja, de três a sete minutos) se o valor aleatório X cair no intervalo (0; 4). A probabilidade de cair em um determinado intervalo é encontrada pela fórmula: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(0< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Expectativa matemática de uma variável aleatória contínua uniformemente distribuída X - o tempo de espera do passageiro, encontramos pela fórmula: M(X)=(a+b)/2. M (X) \u003d (0 + 7) / 2 \u003d 7/2 \u003d 3.5.
5. O desvio padrão de uma variável aleatória contínua uniformemente distribuída X - o tempo de espera do passageiro, encontramos pela fórmula: σ(X)=√D=(b-a)/2√3. σ(X)=(7-0)/2√3=7/2√3≈2,02.
Tarefa 2.
A distribuição exponencial é dada para x ≥ 0 pela densidade f(x) = 5e – 5x. Necessário: a) escreva uma expressão para a função de distribuição; b) encontre a probabilidade de que, como resultado do teste, X caia no intervalo (1; 4); c) encontre a probabilidade de que como resultado do teste X ≥ 2; d) calcule M(X), D(X), σ(X).
Solução. 1. Uma vez que, por condição, distribuição exponencial , então da fórmula para a densidade de distribuição de probabilidade da variável aleatória X obtemos λ = 5. Então a função de distribuição será semelhante a:
2. A probabilidade de que como resultado do teste X caia no intervalo (1; 4) será encontrada pela fórmula:
P(a< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. A probabilidade de que como resultado do teste X ≥ 2 será encontrada pela fórmula: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
Р(Х≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Encontramos para a distribuição exponencial:
- expectativa matemática de acordo com a fórmula M(X) =1/λ = 1/5 = 0,2;
- dispersão de acordo com a fórmula D (X) \u003d 1 / λ 2 \u003d 1/25 \u003d 0,04;
- desvio padrão de acordo com a fórmula σ(X) = 1/λ = 1/5 = 1,2.
A função de distribuição neste caso, conforme (5.7), terá a forma:
onde: m é a expectativa matemática, s é o desvio padrão.
A distribuição normal também é chamada de Gaussiana em homenagem ao matemático alemão Gauss. O fato de uma variável aleatória ter uma distribuição normal com parâmetros: m,, é denotado da seguinte forma: N (m, s), onde: m =a =M ;
Muitas vezes, em fórmulas, a expectativa matemática é denotada por uma . Se uma variável aleatória é distribuída de acordo com a lei N(0,1), ela é chamada de valor normalizado ou padronizado. A função de distribuição para ele tem a forma:
|
|
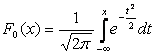 .
.O gráfico da densidade da distribuição normal, que é chamada de curva normal ou curva gaussiana, é mostrado na Fig. 5.4.

Arroz. 5.4. Densidade de distribuição normal
A determinação das características numéricas de uma variável aleatória por sua densidade é considerada em um exemplo.
Exemplo 6.
Uma variável aleatória contínua é dada pela densidade de distribuição: ![]() .
.
Determine o tipo de distribuição, encontre a expectativa matemática M(X) e a variância D(X).
Comparando a densidade de distribuição dada com (5.16), podemos concluir que a lei de distribuição normal com m =4 é dada. Portanto, expectativa matemática M(X)=4, variância D(X)=9.
Desvio padrão s=3.
A função de Laplace, que tem a forma:
|
|
 ,
,está relacionado com a função de distribuição normal (5.17), pela relação:
F 0 (x) \u003d F (x) + 0,5.
A função de Laplace é ímpar.
Ô(-x)=-Ô(x).
Os valores da função de Laplace Ф(х) são tabulados e retirados da tabela de acordo com o valor de x (ver Apêndice 1).
A distribuição normal de uma variável aleatória contínua desempenha um papel importante na teoria da probabilidade e na descrição da realidade; é muito difundida em fenômenos naturais aleatórios. Na prática, muitas vezes existem variáveis aleatórias que são formadas precisamente como resultado da soma de muitos termos aleatórios. Em particular, a análise dos erros de medição mostra que eles são a soma de vários tipos de erros. A prática mostra que a distribuição de probabilidade de erros de medição está próxima da lei normal.
Usando a função de Laplace, pode-se resolver problemas de cálculo da probabilidade de cair em um determinado intervalo e um determinado desvio de uma variável aleatória normal.


