Med vars hjälp simuleras många verkliga processer. Och det vanligaste exemplet är kollektivtrafikens tidtabell. Antag att en viss buss (trolleybuss/spårvagn) körs var tionde minut och du stannar vid ett slumpmässigt tillfälle. Vad är sannolikheten att bussen kommer inom 1 minut? Uppenbarligen 1/10. Vad är sannolikheten att du kommer att behöva vänta 4-5 minuter? Samma. Vad är sannolikheten att du kommer att behöva vänta på en buss i mer än 9 minuter? En tiondel!
Låt oss överväga några ändlig intervall, låt det för visshetens skull vara ett segment. Om slumpmässigt värde har konstant sannolikhetsfördelningstäthet på ett givet segment och noll densitet utanför det, då säger de att det är fördelat jämnt. I det här fallet kommer densitetsfunktionen att vara strikt definierad: 
Ja, om längden på segmentet (se ritning)är , då är värdet oundvikligen lika - så att enhetsarean för rektangeln erhålls och den observeras känd egendom:
Låt oss kontrollera det formellt:
, etc. Ur en sannolikhetssynpunkt innebär detta att den stokastiska variabeln tillförlitligt kommer att ta ett av segmentets värden..., eh, jag börjar sakta bli en tråkig gubbe =)
Kärnan i enhetlighet är att oavsett inre gap bestämd längd vi har inte övervägt (kom ihåg "buss" minuterna)– sannolikheten att en slumpvariabel tar ett värde från detta intervall kommer att vara densamma. På ritningen har jag skuggat tre sådana sannolikheter - återigen understryker jag det de bestäms av områden, inte funktionsvärden!
Låt oss överväga en typisk uppgift:
Exempel 1
En kontinuerlig slumpvariabel specificeras av dess distributionstäthet: ![]()
Hitta konstanten, beräkna och komponera fördelningsfunktionen. Bygg grafer. Hitta
Allt du kan drömma om med andra ord :)
Lösning: sedan på intervallet (ändligt intervall) ![]() , då har den slumpmässiga variabeln en enhetlig fördelning, och värdet på "ce" kan hittas med den direkta formeln
, då har den slumpmässiga variabeln en enhetlig fördelning, och värdet på "ce" kan hittas med den direkta formeln ![]() . Men det är bättre på ett allmänt sätt - att använda en egenskap:
. Men det är bättre på ett allmänt sätt - att använda en egenskap:
...varför är det bättre? Så att det inte finns några onödiga frågor ;)
Så densitetsfunktionen är: 
Låt oss rita. Värderingar omöjlig
, och därför placeras feta prickar nedan: 
Som en snabb kontroll, låt oss beräkna arean av rektangeln: ![]() , etc.
, etc.
Låt oss hitta förväntat värde, och du kan förmodligen redan gissa vad det är lika med. Kom ihåg "10-minuters" bussen: if slumpvis närmar sig hållplatsen i många, många dagar, alltså genomsnitt du måste vänta på honom i 5 minuter.
Ja, det stämmer - förväntningen bör vara exakt i mitten av "händelse"-intervallet:
, som förväntat.
Låt oss beräkna variansen med hjälp av formel ![]() . Och här behöver du ett öga och ett öga när du beräknar integralen:
. Och här behöver du ett öga och ett öga när du beräknar integralen:
Således, dispersion: ![]()
Låt oss komponera distributionsfunktion ![]() . Inget nytt här:
. Inget nytt här:
1) om , då och ![]() ;
;
2) om , då och:
3) och slutligen när ![]() , Det är därför:
, Det är därför:
Som ett resultat: 
Låt oss göra ritningen: 
På "live"-intervallet, distributionsfunktionen växande linjär, och detta är ytterligare ett tecken på att vi har en likformigt fördelad slumpvariabel. Jo, naturligtvis, trots allt derivat linjär funktion- det finns en konstant.
Den erforderliga sannolikheten kan beräknas på två sätt, med hjälp av funna distributionsfunktionen:
eller med en viss integral av densitet: 
Den som gillar det.
Och här kan du också skriva svar: , , graferna är byggda längs lösningen.
, graferna är byggda längs lösningen.
... "det är möjligt" eftersom det vanligtvis inte finns något straff för dess frånvaro. Vanligtvis;)
Det finns speciella formler för att beräkna en enhetlig slumpvariabel, som jag föreslår att du härleder själv:
Exempel 2
En kontinuerlig stokastisk variabel ges av densitet  .
.
Beräkna den matematiska förväntan och variansen. Förenkla resultatet så mycket som möjligt (förkortade multiplikationsformler att hjälpa).
De resulterande formlerna är bekväma att använda för verifiering; kontrollera i synnerhet problemet du just löste genom att ersätta specifika värden för "a" och "b" i dem. Kort lösning längst ner på sidan.
Och i slutet av lektionen kommer vi att titta på ett par "text"-problem:
Exempel 3
Skaldelningsvärdet för mätanordningen är 0,2. Instrumentavläsningar avrundas till närmaste hela division. Om du antar att avrundningsfelen är jämnt fördelade, hitta sannolikheten att den vid nästa mätning inte kommer att överstiga 0,04.
För bättre förståelse lösningar Låt oss föreställa oss att det här är någon slags mekanisk anordning med en pil, till exempel en våg med ett divisionsvärde på 0,2 kg, och vi måste väga en gris i en poke. Men inte för att ta reda på hans fethet - nu blir det viktigt VAR pilen stannar mellan två intilliggande divisioner.
Låt oss betrakta en slumpvariabel - distans pilar från närmast vänster division. Eller från den närmaste till höger, det spelar ingen roll.
Låt oss komponera sannolikhetstäthetsfunktionen:
1) Eftersom avståndet inte kan vara negativt, då på intervallet . Logisk.
2) Av villkoret följer att vågens pil med lika sannolikhet kan stanna var som helst mellan divisionerna *
, inklusive själva divisionerna, och därför på intervallet: ![]()
* Detta är ett väsentligt villkor. Så, till exempel, när man väger bitar av bomull eller kilogram salt, kommer enhetligheten att upprätthållas över mycket smalare intervall.
3) Och eftersom avståndet från NÄRMASTE vänstra divisionen inte kan vara större än 0,2, så är också at lika med noll.
Således: 
Det bör noteras att ingen frågade oss om densitetsfunktionen, och jag presenterade dess kompletta konstruktion uteslutande i kognitiva kedjor. När du är klar med uppgiften räcker det att bara skriva ner den 2:a punkten.
Låt oss nu svara på frågan om problemet. När kommer felet vid avrundning till närmaste division inte överstiga 0,04? Detta kommer att hända när pilen inte stannar längre än 0,04 från vänster division till höger eller inte längre än 0,04 från höger division vänster. På ritningen skuggade jag motsvarande områden: 
Det återstår att hitta dessa områden använda integraler. I princip kan de beräknas "på skolans sätt" (som områden med rektanglar), men enkelheten förstås inte alltid;)
Förbi satsen om addition av sannolikheter för oförenliga händelser:
– sannolikheten att avrundningsfelet inte överstiger 0,04 (40 gram för vårt exempel)
Det är lätt att förstå att det maximala möjliga avrundningsfelet är 0,1 (100 gram) och därför sannolikheten att avrundningsfelet inte överstiger 0,1 lika med ett. Och från detta följer förresten en annan, enklare lösning, där du måste överväga den slumpmässiga variabeln – avrundningsfel till närmaste division. Men den första metoden kom till mig först :)
Svar: 0,4
Och en punkt till om uppgiften. Villkoret kan innehålla fel. Inte avrundning, och om slumpmässig fel själva måtten, vilket vanligtvis är (men inte alltid), fördelas enligt normallagen. Således, Bara ett ord kan radikalt förändra ditt beslut! Var uppmärksam och förstå innebörden av uppgifterna!
Och så fort allt går i en cirkel tar våra fötter oss till samma stopp:
Exempel 4
Bussar på en viss rutt går strikt enligt tidtabell och var 7:e minut. Komponera en densitetsfunktion av en slumpvariabel - väntetiden för nästa buss av en passagerare som slumpmässigt närmade sig hållplatsen. Hitta sannolikheten att han inte väntar på bussen mer än tre minuter. Hitta fördelningsfunktionen och förklara dess meningsfulla innebörd.
Som ett exempel på en kontinuerlig stokastisk variabel, betrakta en stokastisk variabel X likformigt fördelad över intervallet (a; b). Slumpvariabeln X sägs vara jämnt fördelat på intervallet (a; b), om dess distributionstäthet inte är konstant på detta intervall:
Från normaliseringsvillkoret bestämmer vi värdet på konstanten c. Arean under fördelningsdensitetskurvan ska vara lika med enhet, men i vårt fall är det arean av en rektangel med bas (b - α) och höjd c (fig. 1). 
Ris. 1 Enhetlig distributionstäthet
Härifrån hittar vi värdet på konstanten c: ![]()
Så densiteten för en enhetligt fördelad slumpvariabel är lika med 
Låt oss nu hitta fördelningsfunktionen med formeln:
1) för ![]()
2) för
3) för 0+1+0=1.
Således, 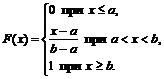
Fördelningsfunktionen är kontinuerlig och minskar inte (Fig. 2). 
Ris. 2 Fördelningsfunktion för en enhetligt fördelad stokastisk variabel
Vi hittar matematisk förväntan på en enhetligt fördelad stokastisk variabel enligt formeln:
Spridning av enhetlig fördelning beräknas med formeln och är lika med
Exempel nr 1. Skaldelningsvärdet för mätanordningen är 0,2. Instrumentavläsningar avrundas till närmaste hela division. Hitta sannolikheten för att ett fel kommer att göras under räkningen: a) mindre än 0,04; b) stor 0,02
Lösning. Avrundningsfelet är en slumpvariabel som är likformigt fördelad över intervallet mellan intilliggande heltalsdivisioner. Låt oss betrakta intervallet (0; 0,2) som en sådan division (Fig. a). Avrundning kan utföras både mot vänster gräns - 0 och mot höger - 0,2, vilket innebär att ett fel mindre än eller lika med 0,04 kan göras två gånger, vilket måste beaktas vid beräkning av sannolikheten: 

P = 0,2 + 0,2 = 0,4
För det andra fallet kan felvärdet också överstiga 0,02 på båda divisionsgränserna, det vill säga det kan vara antingen mer än 0,02 eller mindre än 0,18. 
Då är sannolikheten för ett fel så här:
Exempel nr 2. Det antogs att stabiliteten i den ekonomiska situationen i landet (frånvaro av krig, naturkatastrofer, etc.) under de senaste 50 åren kan bedömas utifrån arten av befolkningsfördelningen efter ålder: i en lugn situation bör det vara enhetlig. Som ett resultat av studien erhölls följande data för ett av länderna.
Finns det någon anledning att tro att det rådde instabilitet i landet?Vi utför lösningen med hjälp av en miniräknare Testar hypoteser. Tabell för beräkning av indikatorer.
| Grupper | Mittpunkten av intervallet, x i | Kvantitet, f i | x i * f i | Ackumulerad frekvens, S | |x - x av |*f | (x - x medel) 2 *f | Frekvens, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Vägt genomsnitt
Variationsindikatorer.
Absoluta variationer.
Variationsintervallet är skillnaden mellan maximi- och minimivärdena för den primära seriekarakteristiken.
R = X max - X min
R = 70 - 0 = 70
Dispersion- kännetecknar spridningsmåttet runt dess medelvärde (ett mått på spridning, d.v.s. avvikelse från genomsnittet).

Standardavvikelse.
Varje värde i serien skiljer sig från medelvärdet på 43 med högst 23,92
Testa hypoteser om typen av distribution.
4. Testa hypotesen om jämn fördelning allmänna befolkningen.
För att testa hypotesen om den enhetliga fördelningen av X, dvs. enligt lagen: f(x) = 1/(b-a) i intervallet (a,b)
nödvändig:
1. Uppskatta parametrarna a och b - ändarna av intervallet där möjliga värden på X observerades, med hjälp av formlerna (tecknet * anger parameteruppskattningar):
2. Hitta sannolikhetstätheten för den förväntade fördelningen f(x) = 1/(b * - a *)
3. Hitta de teoretiska frekvenserna:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(xi - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Jämför empiriska och teoretiska frekvenser med hjälp av Pearson-kriteriet, med antalet frihetsgrader k = s-3, där s är antalet initiala samplingsintervall; om en kombination av små frekvenser, och därför själva intervallen, utfördes, så är s antalet intervall som återstår efter kombinationen.
Lösning:
1. Hitta uppskattningar av parametrarna a * och b * för den enhetliga fördelningen med hjälp av formlerna:
2. Hitta densiteten för den antagna enhetliga fördelningen:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Låt oss hitta de teoretiska frekvenserna:
n 1 = n*f(x)(x 1 - a *) = 1 * 0,0121(10-1,58) = 0,1
n 8 = n*f(x)(b * - x 7) = 1 * 0,0121(84,42-70) = 0,17
De återstående n s kommer att vara lika med:
n s = n*f(x)(xi - x i-1)
| i | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Total | 1 | 0.0532 |
Därför är den kritiska regionen för denna statistik alltid högersidig: , om distributionstätheten är konstant på detta segment och utanför det är den lika med 0.
Den enhetliga fördelningskurvan visas i fig. 3.13.

Ris. 3.13.
Värden/ (X) vid extrema punkter A Och b tomt (a, b) indikeras inte, eftersom sannolikheten att träffa någon av dessa punkter för en kontinuerlig slumpvariabel Xär lika med 0.
Förväntning på en slumpvariabel X, med en enhetlig fördelning över området [a, d], /« = (a + b)/2. Variansen beräknas med hjälp av formeln D =(b- a)2/12, därav st = (b - a)/3,464.
Modellering av slumpvariabler. För att modellera en slumpvariabel måste du känna till dess distributionslag. Det mest allmänna sättet att erhålla en sekvens av slumptal fördelade enligt en godtycklig lag är en metod som bygger på deras bildning från en initial sekvens av slumptal fördelade i intervallet (0; 1) enligt en enhetlig lag.
Jämnt fördelat i intervallet (0; 1) kan sekvenser av slumptal erhållas på tre sätt:
- använda speciellt förberedda tabeller med slumptal;
- använda fysiska slumptalsgeneratorer (till exempel kasta ett mynt);
- algoritmisk metod.
För sådana tal bör den matematiska förväntan vara lika med 0,5 och variansen ska vara 1/12. Om du behöver ett slumptal X var i intervallet ( A; b), skiljer sig från (0; 1), måste du använda formeln X=a + (b-a)r, Var G- ett slumptal från intervallet (0; 1).
På grund av att nästan alla modeller är implementerade på en dator, används nästan alltid en algoritmisk generator (RNG) inbyggd i datorn för att få slumptal, även om det inte är något problem att använda tabeller som tidigare har konverterats till elektronisk form . Det bör beaktas att med den algoritmiska metoden får vi alltid pseudoslumptal, eftersom varje efterföljande genererat nummer beror på det föregående.
I praktiken är det alltid nödvändigt att skaffa slumptal fördelade enligt en given distributionslag. En mängd olika metoder används för detta. Om det analytiska uttrycket för distributionslagen är känt F, då kan du använda invers funktionsmetod.
Det räcker att spela ett slumptal jämnt fördelat i intervallet från 0 till 1. Eftersom funktionen Fändras också i ett givet intervall, sedan slumptalet X kan bestämmas genom att ta den inversa funktionen från en graf eller analytiskt: x = F"(g). Här G- ett tal genererat av RNG i intervallet från 0 till 1; xt- den resulterande slumpvariabeln. Grafiskt visas essensen av metoden i fig. 3.14.

Ris. 3.14. Illustration av den inversa funktionsmetoden för att generera slumpmässiga händelser X, vars värden distribueras kontinuerligt. Figuren visar grafer över sannolikhetstäthet och integral sannolikhetstäthet från X
Låt oss betrakta den exponentiella distributionslagen som ett exempel. Fördelningsfunktionen för denna lag har formen F(x) = 1 -exp(-br). Därför att G Och F i denna metod antas vara likartade och belägna i samma intervall, då ersätter F för ett slumptal r har vi G= 1 - exp(-bg). Uttrycker önskad kvantitet X från detta uttryck (d.v.s. omvända exp()-funktionen) får vi x = -/X? 1p(1 -G). Eftersom i statistisk mening (1 - r) och G - det är samma sak då x = -УХ 1p(g).
Algoritmer för modellering av några vanliga lagar för distribution av kontinuerliga slumpvariabler ges i tabell. 3.10.
Till exempel är det nödvändigt att modellera laddningstid, som fördelas enligt en normal lag. Det är känt att den genomsnittliga laddningstiden är 35 minuter och standardavvikelsen för realtid från medelvärdet är 10 minuter. Det vill säga enligt förutsättningarna för problemet t x = 35, c x= 10. Då kommer värdet på den slumpmässiga variabeln att beräknas enligt formeln R= ?r, var G. - slumpmässiga tal från RNG i intervallet, n = 12. Talet 12 valdes som tillräckligt stort baserat på sannolikhetsteorems centrala gränssats (Lyapunovs sats): ”För ett stort antal N slumpmässiga variabler X med någon distributionslag är deras summa ett slumptal med en normalfördelningslag." Sedan det slumpmässiga värdet X= o (7? - 1/2) + t x = 10(7? -3) + 35.
Tabell 3.10
Algoritmer för modellering av slumpvariabler
Simulering av en slumpmässig händelse. En slumpmässig händelse innebär att en händelse har flera utfall och vilket utfall som kommer att inträffa igen bestäms endast av dess sannolikhet. Det vill säga resultatet väljs slumpmässigt, med hänsyn till dess sannolikhet. Låt oss till exempel säga att vi vet sannolikheten för att producera defekta produkter R= 0,1. Du kan simulera förekomsten av denna händelse genom att spela ett likformigt fördelat slumptal från intervallet 0 till 1 och bestämma vilket av de två intervallen (från 0 till 0,1 eller från 0,1 till 1) det föll i (Fig. 3.15). Om siffran faller inom intervallet (0; 0,1) så släpptes en defekt produkt, det vill säga händelsen inträffade, annars inträffade inte händelsen (en standardprodukt släpptes). Med ett betydande antal experiment kommer frekvensen av siffror som faller i intervallet från 0 till 0,1 att närma sig sannolikheten P= 0,1, och frekvensen av siffror som faller i intervallet från 0,1 till 1 kommer att närma sig P = 0,9.

Ris. 3.15.
Händelserna kallas oförenlig, om sannolikheten för att dessa händelser inträffar samtidigt är 0. Det följer att den totala sannolikheten för en grupp av inkompatibla händelser är lika med 1. Låt oss beteckna med ett r jag, en händelser och genom P]9 P2, ..., R sid- Sannolikheten för att enskilda händelser ska inträffa. Eftersom händelserna är oförenliga är summan av sannolikheterna för att de inträffar lika med 1: P x + P 2 + ... +Pn= 1. För att simulera förekomsten av en av händelserna använder vi återigen en slumptalsgenerator, vars värde också alltid ligger i intervallet från 0 till 1. Låt oss plotta segmenten på ett enhetsintervall P r P v ..., R sid. Det är tydligt att summan av segmenten kommer att bilda exakt ett enhetsintervall. Punkten som motsvarar det tappade talet från slumptalsgeneratorn på detta intervall kommer att peka på ett av segmenten. Följaktligen kommer slumpmässiga tal att dyka upp i större segment oftare (sannolikheten att dessa händelser inträffar är större!), och i mindre segment - mer sällan (Fig. 3.16).
Vid behov, modellering gemensamma evenemang de måste göras oförenliga. Till exempel för att simulera förekomsten av händelser för vilka sannolikheter ges R(a) = 0,7; P(a 2)= 0,5 och P(a ]9 a 2)= 0,4, bestämmer vi alla möjliga inkompatibla utfall av händelser a g a 2 och deras samtidiga utseende:
- 1. Samtidigt inträffande av två händelser P(b () = P(a L , a 2) = 0,4.
- 2. Händelse a ] P(b 2) = P(a y) - P(a ( , a 2) = 0,7 - 0,4 = 0,3.
- 3. Händelse a 2 P(b 3) = P(a 2) - P(a g a 2) = 0,5 - 0,4 = 0,1.
- 4. Inga händelser inträffar P(b 4) = 1 - (P(b) + P(b 2) + + P(b 3)) =0,2.
Nu är sannolikheterna för förekomsten av oförenliga händelser b måste representeras på talaxeln i form av segment. Genom att erhålla nummer med hjälp av RNG bestämmer vi deras tillhörighet till ett visst intervall och erhåller implementeringen av gemensamma händelser A.

Ris. 3.16.
Stöts ofta på i praktiken system av slumpvariabler, dvs sådana två (eller flera) olika slumpvariabler X, U(och andra) som är beroende av varandra. Till exempel om en händelse inträffar X och fick något slumpmässigt värde, sedan händelsen U händer, om än av en slump, men med hänsyn till det faktum att X har redan fått en viss betydelse.
Till exempel, om som X Om ett stort antal visas, då som U ett tillräckligt stort antal bör också visas (om korrelationen är positiv, och vice versa, om den är negativ). Inom transporter förekommer sådana beroenden ganska ofta. Längre förseningar är mer sannolika på rutter av betydande längd osv.
Om de slumpmässiga variablerna är beroende, alltså
f(x)=f(xl)f(x 2 x l)f(x 3 x 2,xl)- ... -/(xjx, r X„ , ...,x 2 ,x t), Var x. | x._v x (- slumpmässigt beroende variabler: bortfall X. förutsatt att de ramlade ut x._ (9 x._ ( ,...,*,) - villkorlig densitet
sannolikheten att inträffa x.> om du ramlade ut x._(9 ..., x ( ; f(x) - sannolikhet för förekomst av vektor x av slumpmässigt beroende variabler.
Korrelationskoefficient q visar hur nära relaterade händelser är Hee W. Om korrelationskoefficienten är lika med ett, så beror händelserna Hee Woo en-till-en: samma värde X matchar ett värde U(Fig. 3.17, A) . På q, nära enhet, bilden som visas i fig. 3.17, b, dvs ett värde X Flera värden på Y kan redan överensstämma (mer exakt, ett av flera värden på Y, bestämt slumpmässigt); dvs i denna händelse X Och Y mindre korrelerade, mindre beroende av varandra.

Ris. 3.17. Typ av beroende av två slumpvariabler med en positiv korrelationskoefficient: a- kl q = 1; b - vid 0 q kl q, nära O
Och slutligen, när korrelationskoefficienten tenderar till noll, uppstår en situation där vilket värde som helst X kan motsvara valfritt värde Y, dvs händelser X Och Y oberoende eller nästan oberoende av varandra, korrelerar inte med varandra (Fig. 3.17, V).
Låt oss till exempel ta normalfördelningen som den vanligaste. Den matematiska förväntan indikerar de mest sannolika händelserna, här är antalet händelser större och grafen över händelser tätare. En positiv korrelation indikerar att stora slumpvariabler X orsaka generering av stora Y. Noll och nära noll korrelation visar att värdet av den slumpmässiga variabeln Xär inte på något sätt relaterat till ett specifikt värde på en slumpvariabel Y. Det är lätt att förstå vad som har sagts om vi först föreställer oss fördelningarna f(X) och/(U) separat, och länka dem sedan till ett system, som visas i Fig. 3.18.
I det aktuella exemplet Hee Y fördelas enligt normallagen med motsvarande värden t x, a och den där, A,. Korrelationskoefficienten för två slumpmässiga händelser anges q, dvs slumpvariabler X och U är beroende av varandra, U är inte helt slumpmässigt.
Då kommer en möjlig algoritm för att implementera modellen att vara följande:
1. Sex slumptal jämnt fördelade över intervallet dras: b r b:, b i, b 4 , b 5 b 6; deras summa hittas S:
S = b. Ett normalfördelat slumptal n hittas: med följande formel: x = a (5 - 6) + t x.
- 2. Enligt formeln t!x = den där + qoJo x (x -t x)är den matematiska förväntningen t y1x(skylt u/x betyder att y kommer att ta slumpmässiga värden, med hänsyn till villkoret att * redan har tagit vissa specifika värden).
- 3. Enligt formeln = en d/l -C 2 standardavvikelsen för a hittas.
4. 12 slumptal r dras jämnt fördelade över intervallet; deras summa hittas k: k = Zr. Hitta ett normalfördelat slumptal på enligt följande formel: y = °Jk-6) + mr/x.

Ris. 3.18.
Händelseflödesmodellering. När det är många händelser och de följer efter varandra bildas de flöde. Observera att händelserna måste vara homogena, d.v.s. något liknande varandra. Till exempel utseendet på förare på bensinstationer som vill tanka sin bil. Det vill säga homogena händelser bildar en viss serie. Man tror att de statistiska egenskaperna för detta 146
fenomen (intensiteten i händelseflödet) ges. Händelseflödets intensitet anger hur många sådana händelser som inträffar i genomsnitt per tidsenhet. Men exakt när varje specifik händelse kommer att inträffa måste bestämmas med hjälp av modelleringsmetoder. Det är viktigt att när vi genererar till exempel 1000 händelser på 200 timmar, kommer deras antal att vara ungefär lika med den genomsnittliga intensiteten av händelser 1000/200 = 5 händelser per timme. Detta är ett statistiskt värde som kännetecknar detta flöde som helhet.
Flödesintensiteten på sätt och vis är den matematiska förväntan på antalet händelser per tidsenhet. Men i verkligheten kan det visa sig att 4 händelser dyker upp på en timme, 6 i en annan, även om det i genomsnitt är 5 händelser per timme, så ett värde räcker inte för att karakterisera flödet. Den andra kvantiteten som kännetecknar hur stor spridningen av händelser är i förhållande till den matematiska förväntan är, som tidigare, spridning. Det är detta värde som bestämmer slumpmässigheten i händelsen av en händelse, den svaga förutsägbarheten i ögonblicket för dess inträffande.
Det finns slumpmässiga strömmar:
- vanlig - sannolikheten för att två eller flera händelser ska inträffa samtidigt är noll;
- stationär - frekvens av händelser X permanent;
- utan efterverkan - sannolikheten för att en slumpmässig händelse inträffar beror inte på det ögonblick då tidigare händelser inträffade.
Vid modellering av QS, i den överväldigande majoriteten av fallen, beaktas det Poisson (enklaste) flöde - vanligt flöde utan efterverkan, där sannolikheten för ankomst i ett tidsintervall t slät T kraven ges av Poisson-formeln:
Ett Poissonflöde kan vara stationärt om A.(/) = const(/), eller icke-stationärt annars.
I ett Poissonflöde är sannolikheten att ingen händelse inträffar
I fig. 3.19 visar beroendet R från tid. Uppenbarligen, ju längre observationstiden är, desto mindre sannolikt är det att ingen händelse inträffar. Dessutom, ju högre värde X, ju brantare grafen går, dvs desto snabbare minskar sannolikheten. Detta motsvarar det faktum att om frekvensen av händelser är hög, så minskar sannolikheten att händelsen inte inträffar snabbt med observationstiden.

Ris. 3.19.
Sannolikhet för att minst en händelse inträffar P = 1 - skhr(-Ad), sedan P + P = . Det är uppenbart att sannolikheten för att minst en händelse inträffar tenderar att bli enhetlig över tiden, det vill säga med lämplig långtidsobservation kommer händelsen definitivt att inträffa förr eller senare. I betydelsen av Rär lika med r och uttrycker därför / från definitionsformeln R, Slutligen, för att bestämma intervallen mellan två slumpmässiga händelser vi har
![]()
Var G- ett slumptal likformigt fördelat från 0 till 1, vilket erhålls med RNG; t- intervall mellan slumpmässiga händelser (slumpmässig variabel).
Ta som ett exempel flödet av bilar som anländer till terminalen. Bilar anländer slumpmässigt - i genomsnitt 8 per dag (flödeshastighet X= 8/24 bilar/h). Det är nödvändigt att röka- 148
dela upp denna process T= 100 timmar Genomsnittligt tidsintervall mellan bilar / = 1/L. = 24/8 = 3 timmar.
I fig. Figur 3.20 visar resultatet av simuleringen - de ögonblick då bilar anlände till terminalen. Som kan ses, i bara perioden T = 100 terminaler behandlade N=33 bil. Om vi kör simuleringen igen, då N kan visa sig vara lika, till exempel 34, 35 eller 32. Men i genomsnitt för TILL algoritmen körs N kommer att vara lika med 33,333.
Ris. 3,20.
Om det är känt att flödet är inte vanligt då är det nödvändigt att modellera, förutom det ögonblick då händelsen inträffade, även antalet händelser som kan inträffa i detta ögonblick. Till exempel kommer bilar till terminalen vid slumpmässiga tidpunkter (ett vanligt flöde av bilar). Men samtidigt kan bilar ha olika (slumpmässiga) mängder last. I detta fall talas om lastflödet som ström av extraordinära händelser.
Låt oss överväga problemet. Det är nödvändigt att fastställa stilleståndstiden för lastningsutrustning vid terminalen om AUK-1.25-containrar levereras till terminalen av fordon. Flödet av bilar följer Poissons lag, medelintervallet mellan bilar är 0,5 chD = 1/0,5 = 2 bilar/timme. Antalet containrar i en bil varierar enligt normallagen med ett medelvärde T= 6 och a = 2. I det här fallet kan minimum vara 2 och max 10 behållare. Lossningstiden för en container är 4 minuter och 6 minuter krävs för teknisk drift. Algoritmen för att lösa detta problem, byggd på principen om sekventiell postning av varje applikation, visas i fig. 3.21.
Efter inmatning av initialdata startar simuleringscykeln tills den angivna simuleringstiden uppnås. Med hjälp av RNG får vi ett slumptal och bestämmer sedan tidsintervallet innan bilen kommer. Vi markerar det resulterande intervallet på tidsaxeln och simulerar antalet containrar på baksidan av det ankommande fordonet.
Vi kontrollerar det resulterande numret för ett acceptabelt intervall. Därefter beräknas lossningstiden och summeras i räknaren för lastutrustningens totala drifttid. Villkoret kontrolleras: om fordonets ankomstintervall är större än lossningstiden, så summeras skillnaden mellan dem i utrustningens stilleståndsräknare.

Ris. 3.21.
Ett typiskt exempel för ett QS-system skulle vara driften av en lastpunkt med flera stolpar, som visas i fig. 3.22.

Ris. 3.22.
För klarhet i modelleringsprocessen kommer vi att konstruera ett tidsdiagram över QS:s funktion, som reflekterar på varje linje (tidsaxel /) tillståndet för ett individuellt element i systemet (Fig. 3.23). Det finns lika många tidslinjer som det finns olika objekt i QS (flöden). I vårt exempel finns det 7 av dem: ett flöde av ansökningar, ett vänteflöde i första hand i kön, ett vänteflöde i andra hand i kön, ett tjänsteflöde i den första kanalen, ett tjänsteflöde i andra kanalen, ett flöde av ansökningar som betjänas av systemet, ett flöde av avvisade ansökningar. För att demonstrera processen för denial of service kommer vi överens om att endast två bilar kan stå i kön för lastning. Om det finns fler av dem skickas de till en annan lastplats.
De simulerade slumpmässiga ögonblicken för mottagande av förfrågningar om bilservice visas på första raden. Den första begäran tas och, eftersom kanalerna för närvarande är lediga, är den inställd för att betjäna den första kanalen. Ansökan 1 överförs till den första kanalens linje. Servicetiden i kanalen är också slumpmässig. Vi hittar på diagrammet tidpunkten för slutet av tjänsten, vilket skjuter upp den genererade tjänstetiden från det ögonblick då tjänsten börjar.
niya och sänk applikationen till raden "Betjänad". Ansökan gick hela vägen till CMO. Nu, enligt principen om sekventiell postning av beställningar, kan du också modellera sökvägen för den andra beställningen.

Ris. 3.23.
Om det vid något tillfälle visar sig att båda kanalerna är upptagna, bör förfrågan läggas i en kö. I fig. 3.23 detta är en applikation 3. Observera att enligt villkoren för uppgiften, till skillnad från kanaler, finns förfrågningar inte i kön under en slumpmässig tid, utan väntar på att en av kanalerna ska bli ledig. Efter att kanalen har släppts höjs begäran till raden för motsvarande kanal och dess service organiseras där.
Om vikten av platsen i kön vid tidpunkten för nästa ansökan kommer är upptagen, ska ansökan skickas till raden "Avvisad". I fig. 3.23 detta är en applikation 6.
Proceduren för att simulera applikationsservice fortsätter under en tid. T. Ju längre denna tid, desto mer exakta blir simuleringsresultaten i framtiden. I verkligheten väljer de för enkla system T, lika med 50-100 timmar eller mer, även om det ibland är bättre att mäta detta värde med antalet granskade ansökningar.
Vi kommer att analysera QS med det exempel som redan diskuterats.
Först måste du vänta på steady state. Vi ignorerar de fyra första förfrågningarna som okarakteristiska, som inträffade under processen att etablera systemets funktion ("modelluppvärmningstid"). Vi mäter observationstiden, låt oss anta att i vårt exempel G = 5 timmar. Vi beräknar antalet servade applikationer från diagrammet N o6c, tomgångstid och andra värden. Som ett resultat kan vi beräkna indikatorer som kännetecknar kvaliteten på QS-operationen:
- 1. Sannolikhet för tjänst R = N,/N= 5/7 = 0,714. För att beräkna sannolikheten för att serva en applikation i systemet räcker det att dela upp antalet ansökningar som kunde serveras över tiden T(se raden "Betjänad"), L/o6s för antalet ansökningar N, som anlände samtidigt.
- 2. Systemgenomströmning A = NJT h = 7/5 = 1,4 bilar/timme. För att beräkna systemkapaciteten räcker det med att dela antalet förfrågningar som serveras N o6c ett tag T, för vilken denna tjänst ägde rum.
- 3. Sannolikhet för misslyckande P = N/N=3/7 = 0,43. För att beräkna sannolikheten för att en begäran nekas tjänst räcker det att dela antalet förfrågningar N som avvisades under T(se raden "Avvisad"), per antal ansökningar N, som ville bli serverad under samma tid, d.v.s. kommit in i systemet. Observera att beloppet R op + R p(k i teorin borde vara lika med 1. I själva verket visade det sig experimentellt att R + R.= 0,714 + 0,43 = 1,144. Denna felaktighet förklaras av det faktum att under observationsperioden T Otillräcklig statistik har ackumulerats för att få ett korrekt svar. Felet för denna indikator är nu 14%.
- 4. Sannolikhet för beläggning av en kanal Р = T r JT H= 0,05/5 = 0,01, där T- upptagen tid för endast en kanal (första eller andra). De tidsintervall under vilka vissa händelser inträffar är föremål för mätningar. Till exempel letar diagrammet efter segment när antingen den första eller andra kanalen är upptagen. I det här exemplet finns ett sådant segment i slutet av diagrammet, 0,05 timmar långt.
- 5. Sannolikhet för beläggning av två kanaler P = T / T = 4,95/5 = 0,99. Diagrammet letar efter segment under vilka både den första och andra kanalen är upptagna samtidigt. I det här exemplet finns det fyra sådana segment, deras summa är 4,95 timmar.
- 6. Genomsnittligt antal upptagna kanaler: /V till -0 P 0 + P X + 2 P, = = 0,01 +2? 0,99= 1,99. För att beräkna hur många kanaler som är upptagna i systemet i genomsnitt räcker det att känna till andelen (sannolikheten för beläggning av en kanal) och multiplicera med vikten av denna andel (en kanal), känna till andelen (sannolikheten för beläggning) av två kanaler) och multiplicera med vikten av denna andel (två kanaler) osv. Den resulterande siffran 1,99 indikerar att av två möjliga kanaler är i genomsnitt 1,99 kanaler laddade. Detta är en hög belastningsgrad, 99,5%, systemet utnyttjar resurserna väl.
- 7. Sannolikhet för stilleståndstid för minst en kanal P*, = Г enkel,/Г = = 0,05/5 = 0,01.
- 8. Sannolikhet för driftstopp för två kanaler samtidigt: P = = T JT = 0.
- 9. Sannolikhet för driftstopp för hela systemet P* =T/T = 0.
- 10. Genomsnittligt antal ansökningar i kön /V з = 0 P(h + 1 Р och + 2Ръ= = 0,34 + 2 0,64 = 1,62 auto. För att bestämma det genomsnittliga antalet applikationer i kön är det nödvändigt att separat bestämma sannolikheten för att det kommer att finnas en applikation P i kön, sannolikheten att det kommer att finnas två applikationer P 23 i kön, etc., och lägga till dem igen med lämpliga vikter.
- 11. Sannolikheten att det kommer att finnas en applikation i kön är P och = = TJTn= 1,7/5 = 0,34 (det finns fyra sådana segment i diagrammet, vilket ger totalt 1,7 timmar).
- 12. Sannolikheten att två ansökningar kommer att stå i kön samtidigt är R ъ= Г 2з /Г = 3,2/5 = 0,64 (det finns tre sådana segment i diagrammet, vilket ger totalt 3,25 timmar).
- 13. Den genomsnittliga väntetiden för en ansökan i kön är G roz = 1,7/4 = 0,425 timmar Det är nödvändigt att räkna ihop alla tidsintervall under vilka en ansökan stod i kön och dividera med antalet ansökningar. Det finns 4 sådana förfrågningar på tidsdiagrammet.
- 14. Genomsnittlig tid för service av en applikation 7' srobsl = 8/5 = 1,6 timmar. Lägg ihop alla tidsintervall under vilka en applikation har betjänats i valfri kanal och dividera med antalet ansökningar.
- 15. Genomsnittlig tid som en applikation finns kvar i systemet: T = T +
g g avg. sjöng ons Häftigt
Om noggrannheten inte är tillfredsställande, bör experimenttiden ökas och därigenom förbättra statistiken. Du kan göra det annorlunda om du kör experiment 154 flera gånger
ett tag T och därefter genomsnitt av värdena för dessa experiment, och kontrollera sedan resultaten mot noggrannhetskriteriet. Denna procedur bör upprepas tills den erforderliga noggrannheten har uppnåtts.
Analys av simuleringsresultat
Tabell 3.11
|
Index |
Menande indikator |
Intressen för ägaren av CMO |
Kundens intressen |
|
Sannolikhet service |
Sannolikheten för service är låg, många kunder lämnar systemet utan service Rekommendation: öka sannolikheten för service |
Sannolikheten för service är låg, var tredje kund vill bli betjänad men kan inte Rekommendation: öka sannolikheten för service |
|
|
Genomsnittligt antal ansökningar i kö |
Nästan alltid innan service står bilen i kö Rekommendation: öka antalet platser i kön, öka genomströmningen |
||
|
Öka genomströmningen Öka antalet platser i kön för att inte tappa potentiella kunder |
Kunder är intresserade av att avsevärt öka genomströmningen för att minska latens och avhopp |
För att besluta om genomförandet av specifika aktiviteter är det nödvändigt att göra en känslighetsanalys av modellen. Mål modellkänslighetsanalysär att fastställa möjliga avvikelser i utgångskarakteristika på grund av ändringar i ingångsparametrar.
Metoder för att bedöma känsligheten hos en simuleringsmodell liknar metoder för att bestämma känsligheten hos vilket system som helst. Om modellens utgångsegenskaper R beror på parametrar associerade med variabla kvantiteter R =/(r g r 2, r), sedan ändringar i dessa
parametrar D r.(/ = 1, ..G) orsaka förändring AR.

I det här fallet handlar känslighetsanalysen av modellen om att studera känslighetsfunktionen dR/etc.
Som ett exempel på känslighetsanalys av en simuleringsmodell, låt oss överväga effekten av att ändra variabla fordonspålitlighetsparametrar på driftseffektiviteten. Som en objektiv funktion använder vi indikatorn för minskade kostnader Zir. För känslighetsanalys använder vi data om driften av vägtåget KamAZ-5410 i stadsförhållanden. Gränser för parameterändring R. för att bestämma modellens känslighet räcker det att bestämma den med expertmedel (tabell 3.12).
För att utföra beräkningar med modellen valdes en baspunkt där de olika parametrarna har värden som motsvarar standarderna. Parametern för stilleståndstidens varaktighet vid utförandet av underhåll och reparationer i dagar har ersatts med en specifik indikator - stilleståndstid i dagar per tusen kilometer N.
Beräkningsresultaten visas i fig. 3.24. Baspunkten är i skärningspunkten mellan alla kurvor. Visat i fig. 3.24 beroenden gör det möjligt för oss att fastställa graden av påverkan av var och en av parametrarna som övervägs på storleken på förändringen i 3. Samtidigt tillåter användningen av naturliga värden för de analyserade kvantiteterna oss inte att fastställa den jämförande grad av påverkan av varje parameter på 3, eftersom dessa parametrar har olika måttenheter. För att övervinna detta kommer vi att välja formen för att tolka beräkningsresultaten i relativa enheter. För att göra detta måste baspunkten flyttas till utgångspunkten för koordinater, och värdena för de föränderliga parametrarna och den relativa förändringen i modellens utgångsegenskaper måste uttryckas i procent. Resultaten av de utförda transformationerna presenteras i fig. 3,25.
Tabell 3.12
Värderingar variabla parametrar

Ris. 3.24.

Ris. 3,25. Inverkan av den relativa förändringen i de olika parametrarna på graden av förändring i
Förändringen av variabla parametrar i förhållande till basvärdet presenteras på en axel. Som framgår av fig. 3.25 leder en ökning av värdet för varje parameter nära baspunkten med 50 % till en ökning av Zpr med 9 % av ökningen av Ta, med mer än 1,5 % av C p, med mindre än 0,5 % av N och till en minskning med 3 med nästan 4 % av ökningen L. Minska med 25 % b cr och D rg leder till en ökning av Z pr respektive med mer än 6 %. Reducerar parametrar med samma mängd N t0, P a g e leder till en minskning av Zpr med 0,2, 0,8 respektive 4,5 %.
De givna beroenden ger en uppfattning om påverkan av en enskild parameter och kan användas vid planering av driften av transportsystemet. Beroende på intensiteten av påverkan på miljön kan de övervägda parametrarna ordnas i följande ordning: D, II, L, C 9 N .
’a 7 k.r 7 t.r 7 t.o
Under drift innebär en förändring av värdet på en indikator en förändring av värdena för andra indikatorer, och den relativa förändringen av var och en av de olika parametrarna med samma värde i det allmänna fallet har en ojämlik fysisk grund. Det är nödvändigt att ersätta den relativa förändringen av värdena för olika parametrar i procent längs abskissaxeln med en parameter som kan fungera som ett enda mått för att bedöma graden av förändring i varje parameter. Det kan antas att värdet av varje parameter vid varje driftögonblick av fordonet har samma ekonomiska vikt i förhållande till värdena för andra variabla parametrar, d.v.s. ur ekonomisk synvinkel, fordonets tillförlitlighet vid varje tidpunkt har en jämviktseffekt på alla parametrar som är associerade med den. Då kommer den erforderliga ekonomiska motsvarigheten att vara tid eller, mer bekvämt, ett års drift.
I fig. Figur 3.26 visar beroenden byggda i enlighet med ovanstående krav. Basvärdet för Zpr antas vara värdet under det första driftåret av fordonet. Värdena för variabla parametrar för varje verksamhetsår bestämdes baserat på resultaten av observationer.

Ris. 3,26.
Under drift beror ökningen av Zpr under de första tre åren främst på värdestegringen H jo, och sedan, under de övervägda driftsförhållandena, spelas huvudrollen för att minska effektiviteten av fordonsanvändning av en ökning av värdena på C pp. För att identifiera påverkan av kvantiteten LKp, i beräkningar likställdes dess värde med fordonets totala körsträcka sedan driftstarten. Funktionstyp 3 =f(L) visar att intensiteten av minskningen är 3 med ökning
etc J v k.r" 7 n.p. J
1 till r reduceras avsevärt.
Som ett resultat av modellens känslighetsanalys är det möjligt att förstå vilka faktorer som behöver påverkas för att förändra den objektiva funktionen. För att förändra faktorer krävs kontrollinsatser vilket är förenat med motsvarande kostnader. Mängden kostnader kan inte vara oändliga, precis som alla resurser är dessa kostnader i verkligheten begränsade. Därför är det nödvändigt att förstå i vilken utsträckning tilldelningen av medel kommer att vara effektiv. Om i de flesta fall kostnaderna ökar linjärt med ökande styrverkan, så växer systemets effektivitet snabbt bara upp till en viss gräns, när även betydande kostnader inte längre ger samma avkastning. Till exempel är det omöjligt att gränslöst öka kraften hos serviceenheter på grund av utrymmesbegränsningar eller det potentiella antalet servade fordon etc.
Om vi jämför kostnadsökningen och systemeffektivitetsindikatorn i samma enheter, kommer det som regel grafiskt att se ut som det som visas i fig. 3.27.

Ris. 3.27.
Från fig. 3.27 det är tydligt att när man tilldelar ett pris C, per enhet av kostnad Z och pris C, per enhet av indikator R dessa kurvor kan läggas till. Kurvor läggs till om de samtidigt behöver minimeras eller maximeras. Om en kurva ska maximeras och den andra ska minimeras, så ska deras skillnad hittas till exempel genom poäng. Då kommer den resulterande kurvan (Fig. 3.28), som tar hänsyn till både effekten av förvaltningen och kostnaderna för detta, att ha ett extremum. Värdet på parametern /?, som tillhandahåller funktionens extremum, är lösningen på syntesproblemet.

Ris. 3,28.
till...
Förutom management R och indikator R det finns en störning i systemen. Störning D= (d v d r...) är en ingångspåverkan, som, till skillnad från styrparametern, inte beror på systemägarens vilja (fig. 3.29). Till exempel låga temperaturer ute och konkurrens minskar tyvärr kundflödet; Utrustningsfel minskar systemets prestanda. Systemägaren kan inte kontrollera dessa kvantiteter direkt. Vanligtvis agerar indignation "för att trotsa" ägaren, vilket minskar effekten R från kontrollinsatser R. Detta beror på att systemet i allmänhet är skapat för att uppnå mål som är ouppnåeliga av sig själva i naturen. En person som organiserar ett system hoppas alltid på att uppnå något mål genom det R. Han lägger kraft på detta R. I detta sammanhang kan vi säga att ett system är en organisation av naturliga komponenter som är tillgängliga för människan och studerade av henne för att uppnå något nytt mål, tidigare ouppnåeligt på andra sätt.

Ris. 3,29.
Om vi tar bort beroendet av indikatorn R från ledningen R igen, men under förhållandena för den framträdande störningen D, då kanske kurvans natur kommer att förändras. Mest troligt kommer indikatorn att vara lägre för samma kontrollvärden, eftersom störningen är negativ, vilket minskar systemets prestanda. Ett system som lämnas åt sig själv, utan ledningsinsatser, upphör att uppnå målet för vilket det skapades. Om vi, som tidigare, konstruerar ett kostnadsberoende och korrelerar det med indikatorns beroende av kontrollparametern, kommer den hittade extremumpunkten att förskjutas (Fig. 3.30) jämfört med fallet med "störning = 0" (se Fig. 3.30). 3,28). Om störningen ökas igen kommer kurvorna att förändras och som en konsekvens kommer läget för extremumpunkten att ändras igen.
Grafen i fig. 3.30 ansluter indikator P, hantering (resurs) R och indignation D i komplexa system, anger hur man bäst agerar för att chefen (organisationen) fattar beslut i systemet. Om kontrollåtgärden är mindre än optimal kommer den totala effekten att minska och en situation med utebliven vinst uppstår. Om kontrollåtgärden är större än optimal, kommer effekten också att minska, eftersom betalningen för kön är 162
En ytterligare ökning av kontrollinsatserna kommer att behöva vara större än vad du får som ett resultat av att använda systemet.

Ris. 3.30.
En simuleringsmodell av systemet för verklig användning måste implementeras på en dator. Detta kan skapas med hjälp av följande verktyg:
- universellt användarprogram såsom en matematisk (MATLAB) eller kalkylbladsprocessor (Excel) eller en DBMS (Access, FoxPro), som gör att du bara kan skapa en relativt enkel modell och som kräver åtminstone grundläggande programmeringskunskaper;
- universellt programmeringsspråk(C++, Java, Basic, etc.), vilket låter dig skapa en modell av vilken komplexitet som helst; men detta är en mycket arbetsintensiv process som kräver att man skriver en stor mängd programkod och långvarig felsökning;
- specialiserat simuleringsspråk, som har färdiga mallar och visuella programmeringsverktyg utformade för att snabbt skapa grunden för en modell. En av de mest kända är UML (Unified Modeling Language);
- simuleringsprogram, som är de mest populära sätten att skapa simuleringsmodeller. De låter dig skapa en modell visuellt, bara i de mest komplexa fallen genom att manuellt skriva programkod för procedurer och funktioner.
Simuleringsprogram är indelade i två typer:
- Universella simuleringspaketär designade för att skapa olika modeller och innehåller en uppsättning funktioner som kan användas för att simulera typiska processer i system för olika ändamål. Populära paket av denna typ är Arena (utvecklat av Rockwell Automation 1", USA), Extendsim (utvecklat av Imagine That Ink., USA), AnyLogic (utvecklat av XJ Technologies, Ryssland) och många andra. Nästan alla universella paket har specialiserade versioner för modellering av specifika klassobjekt.
- Domänspecifika simuleringspaket tjäna för modellering av specifika typer av objekt och har specialiserade verktyg för detta i form av mallar, guider för att visuellt utforma en modell från färdiga moduler, etc.
- Naturligtvis kan två slumpmässiga tal inte unikt bero på varandra, Fig. 3.17 ges för att klargöra begreppet korrelation. 144
- Teknisk och ekonomisk analys i studien av tillförlitligheten hos KamAZ-5410-fordon /Yu. G. Kotikov, I. M. Blankinshtein, A. E. Gorev, A. N. Borisenko; LISI. L.:, 1983. 12 s.-Dep. i CBNTI vid ministeriet för biltransport i RSFSR, nr 135at-D83.
- http://www.rockwellautomation.com.
- http://www.cxtcndsiin.com.
- http://www.xjtek.com.
Som tidigare nämnts, exempel på sannolikhetsfördelningar kontinuerlig slumpvariabel X är:
- enhetlig sannolikhetsfördelning av en kontinuerlig stokastisk variabel;
- exponentiell sannolikhetsfördelning av en kontinuerlig stokastisk variabel;
- normal distribution sannolikheter för en kontinuerlig stokastisk variabel.
Låt oss ge begreppet enhetliga och exponentiella fördelningslagar, sannolikhetsformler och numeriska egenskaper för de funktioner som övervägs.
| Index | Enhetlig distributionslag | Exponentiell distributionslag |
|---|---|---|
| Definition | Kallas uniform sannolikhetsfördelning av en kontinuerlig stokastisk variabel X, vars densitet förblir konstant på segmentet och har formen | Exponentiell (exponentiell) kallas sannolikhetsfördelning av en kontinuerlig stokastisk variabel X, som beskrivs av en densitet som har formen |
 där λ är ett konstant positivt värde |
||
| Distributionsfunktion |  |
|
| Sannolikhet faller in i intervallet |  |
|
| Förväntat värde | ||
| Dispersion |  |
|
| Standardavvikelse |  |
Exempel på att lösa problem i ämnet "Uniforma och exponentiella distributionslagar"
Uppgift 1.
Bussar går strikt enligt tidtabell. Rörelseintervall 7 min. Ta reda på: a) sannolikheten att en passagerare som anländer till en hållplats väntar mindre än två minuter på nästa buss; b) sannolikheten att en passagerare som anländer till en hållplats kommer att vänta minst tre minuter på nästa buss; c) matematisk förväntan och standardavvikelse för den slumpmässiga variabeln X - passagerares väntetid.
Lösning. 1. Enligt villkoren för problemet är en kontinuerlig slumpvariabel X = (passagerarens väntetid) jämnt fördelat mellan ankomsterna av två bussar. Längden på fördelningsintervallet för stokastisk variabel X är lika med b-a=7, där a=0, b=7.
2. Väntetiden blir mindre än två minuter om den slumpmässiga variabeln X faller inom intervallet (5;7). Vi hittar sannolikheten att falla in i ett givet intervall med hjälp av formeln: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(5< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. Väntetiden kommer att vara minst tre minuter (d.v.s. från tre till sju minuter) om den slumpmässiga variabeln X faller inom intervallet (0;4). Vi hittar sannolikheten att falla in i ett givet intervall med hjälp av formeln: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(0< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Den matematiska förväntningen på en kontinuerlig, enhetligt fördelad slumpvariabel X – passagerarens väntetid – kommer att hittas med hjälp av formeln: M(X)=(a+b)/2. M(X) = (0+7)/2 = 7/2 = 3,5.
5. Standardavvikelsen för en kontinuerlig, jämnt fördelad slumpvariabel X – passagerarens väntetid – kommer att hittas med hjälp av formeln: σ(X)=√D=(b-a)/2√3. σ(X)=(7-0)/2√3=7/2√3≈2,02.
Uppgift 2.
Exponentialfördelningen ges för x ≥ 0 av densiteten f(x) = 5e – 5x. Obligatoriskt: a) skriv ner ett uttryck för fördelningsfunktionen; b) hitta sannolikheten att X som ett resultat av testet hamnar i intervallet (1;4); c) hitta sannolikheten att som ett resultat av testet X ≥ 2; d) beräkna M(X), D(X), σ(X).
Lösning. 1. Eftersom villkoret är givet exponentiell fördelning , då får vi från formeln för sannolikhetsfördelningstätheten för den slumpmässiga variabeln X λ = 5. Då kommer fördelningsfunktionen att ha formen:
2. Sannolikheten för att X som ett resultat av testet hamnar i intervallet (1;4) kommer att hittas av formeln:
P(a< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. Sannolikheten att som ett resultat av testet X ≥ 2 kommer att hittas av formeln: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
P(X≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Hitta exponentialfördelningen:
- matematisk förväntan enligt formeln M(X) = 1/λ = 1/5 = 0,2;
- varians enligt formeln D(X) = 1/ λ 2 = 1/25 = 0,04;
- standardavvikelse enligt formeln σ(X) = 1/λ = 1/5 = 1,2.
Distributionsfunktionen i detta fall, enligt (5.7), kommer att ha formen:
där: m – matematisk förväntan, s – standardavvikelse.
Normalfördelningen kallas även Gauss efter den tyske matematikern Gauss. Det faktum att en stokastisk variabel har en normalfördelning med parametrarna: m, betecknas på följande sätt: N (m,s), där: m =a =M ;
Ganska ofta i formler betecknas den matematiska förväntan med A . Om en stokastisk variabel är fördelad enligt lagen N(0,1) så kallas den för en normaliserad eller standardiserad normalvariabel. Distributionsfunktionen för den har formen:
|
|
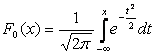 .
.Densitetsgrafen för en normalfördelning, som kallas normalkurva eller gaussisk kurva, visas i fig. 5.4.

Ris. 5.4. Normal fördelningstäthet
Bestämningen av de numeriska egenskaperna för en slumpvariabel genom dess densitet övervägs med hjälp av ett exempel.
Exempel 6.
En kontinuerlig slumpvariabel specificeras av distributionstätheten: ![]() .
.
Bestäm typen av fördelning, hitta den matematiska förväntan M(X) och varians D(X).
Genom att jämföra den givna fördelningstätheten med (5.16) kan vi dra slutsatsen att normalfördelningslagen med m = 4 är given. Därför matematisk förväntan M(X)=4, varians D(X)=9.
Standardavvikelse s=3.
Laplace-funktionen, som har formen:
|
|
 ,
,är relaterad till normalfördelningsfunktionen (5.17), relationen:
Fo (x) = Ф(x) + 0,5.
Laplace-funktionen är udda.
Ф(-x)=-Ф(x).
Värdena för Laplace-funktionen Ф(х) är tabellerade och hämtade från tabellen enligt värdet på x (se bilaga 1).
Normalfördelningen av en kontinuerlig slumpvariabel spelar en viktig roll i sannolikhetsteorin och för att beskriva verkligheten, den är mycket utbredd i slumpmässiga naturfenomen. I praktiken stöter vi väldigt ofta på slumpvariabler som bildas just som ett resultat av summering av många slumpmässiga termer. Speciellt visar en analys av mätfel att de är summan av olika typer av fel. Praxis visar att sannolikhetsfördelningen av mätfel ligger nära normallagen.
Med hjälp av Laplace-funktionen kan du lösa problemet med att beräkna sannolikheten att hamna i ett givet intervall och en given avvikelse för en normal stokastisk variabel.


